Code
# !pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2 ![]()
“Wahrnehmung ist nicht ein Fragment einzelner Sinne, sondern eine Symphonie, in der alle Sinne harmonisch verschmelzen.”, James Gibson, Gründer der ökologischen Psychologie.
In der Geschichte der künstlichen Intelligenz gab es lange Zeit ein ungelöstes Problem: die “Multimodalität (Multimodality)”. Menschen nutzen bei der Wahrnehmung der Welt verschiedene Sinnesmodalitäten (Sehen, Hören, Tasten) gleichzeitig und integrieren diese organisch. Zum Beispiel nehmen wir in einem Café gleichzeitig die Wärme der Kaffeetasse (Tastsinn), den Geruch des Kaffees (Gehör), das Gespräch der umstehenden Menschen (Hörsinn) und die Innenausstattung des Cafés (Sehsinn) wahr, um daraus eine ganzheitliche Erfahrung von “im Café sein” zu formen.
Frühe künstliche Intelligenzmodelle hatten jedoch Schwierigkeiten, diese multimodalen Informationen zu verarbeiten. Die seit den 1950er Jahren beginnenden Forschungen zur künstlichen Intelligenz konzentrierten sich vor allem auf die Verarbeitung einzelner Modalitäten (Text, Bilder, Sprache). Es wurden beachtliche Fortschritte in Bereichen wie Übersetzung und Spracherkennung erzielt, aber das Vereinen dieser, um sie wie ein Mensch zu verstehen, stellte eine ganz andere Herausforderung dar.
In diesem Kapitel untersuchen wir die Kerntheorien und überlebenden Architekturen des multimodalen Deep Learnings. Wir werden uns mit der Frage beschäftigen, auf welche Weise jede Architektur das DNA-Strand von Deep Learning erweitert und weiterentwickelt hat und wie sie zur Lösung komplexer Probleme in der realen Welt beitragen.
Herausforderung: Wie kann man Daten verschiedener Arten, wie Text, Bilder und Audio, in einem Modell zusammenfassen und verarbeiten? Diese Daten unterscheiden sich in ihrer Darstellung, Dimensionen und statistischen Eigenschaften. Wie kann man heterogene Informationen fusionieren, um sinnvolle Repräsentationen zu lernen?
Frust der Forscher: Die Forscher mussten neue Methoden finden, die die einzigartigen Eigenschaften jeder Modalität beibehalten und gleichzeitig ihre Interaktionen effektiv modellieren. Es war notwendig, über eine einfache Verkettung (Concatenation) hinauszugehen und echte Fusion zu erreichen, bei der jede Modalität den Kontext der anderen versteht und komplementäre Informationen bereitstellt.
Multimodale Daten beziehen sich auf die Kombination verschiedener Sinnesmodalitäten, wie Text, Bilder und Audio. Das Verstehen von Kaffeeduft und das Hören von Gesprächen sind für Menschen selbstverständlich.
Warum war multimodales Deep Learning ein schwieriges Problem?
Heterogene Datenrepräsentation: Text, Bilder und Audio unterscheiden sich in ihrer Darstellung, Dimensionen und statistischen Eigenschaften. Die effektive Verarbeitung solcher heterogener Daten in einem Modell war eine Herausforderung.
Komplexität der Informationssynthese: Einfache Verkettung (Concatenation) der Informationen jeder Modalität führt nicht zu echter Fusion. Es ist erforderlich, dass jede Modalität den Kontext der anderen versteht, komplementäre Informationen bereitstellt und manchmal widersprüchliche Informationen ausgleicht.
Mangel an Daten und Ungleichgewicht: Multimodale Daten sind im Vergleich zu unimodalen Daten weniger häufig vorhanden, und es gibt ein Ungleichgewicht in den Daten jeder Modalität. Zum Beispiel gibt es viele Paare von Bildern und Texten, aber seltener finden sich Daten, die Bilder, Texte und Audio kombinieren.
Trotz dieser Herausforderungen hat Deep Learning neue Möglichkeiten für die Verarbeitung multimodaler Daten eröffnet. Seit den 2010er Jahren hat die Entwicklung von Deep-Learning-Technologien, insbesondere die Einführung der Transformer-Architektur, eine entscheidende Rolle bei der Fortschritte im Bereich des multimodalen Deep Learnings gespielt. Dies war ein wichtiger Wendepunkt in der Entwicklung der Deep-Learning-DNA. Der Selbst-Aufmerksamkeits-Mechanismus (self-attention) des Transformers ermöglicht es nicht nur, Beziehungen zwischen Elementen innerhalb einer Modalität effektiv zu modellieren, sondern auch komplexe Wechselwirkungen zwischen verschiedenen Modalitäten. Während bis dahin CNNs für Bilder und RNNs für sequenzielle Daten spezialisiert waren, bot der Transformer eine universelle Architektur mit der Flexibilität, auf verschiedene Modalitäten angewendet zu werden.
Multimodales Deep Learning ist eine essentielle Technologie, die es künstlicher Intelligenz ermöglicht, die Welt wie Menschen zu verstehen und mit ihr zu interagieren. Es geht über das einfache Verarbeiten verschiedener Datenformate hinaus und verbindet organisch die Bedeutungen der einzelnen Daten, um reichhaltigere und präzisere Schlussfolgerungen zu ziehen. So wie verschiedene Bereiche des Gehirns zusammenarbeiten, um komplexe kognitive Funktionen auszuführen, ist multimodales Deep Learning die treibende Kraft, die die Intelligenz von KI auf ein höheres Niveau hebt.
Wichtige Anwendungsgebiete
Visuelle Frage-Antwort (Visual Question Answering, VQA): Eingabe von Bildern und Fragen (Text) und Generierung von Antworten auf diese Fragen. Es geht nicht nur darum, Objekte in einem Bild zu erkennen, sondern auch die Bedeutung des Bildes und der Frage umfassend zu verstehen. Zum Beispiel erfordert eine Antwort auf die Frage “Welche Farbe hat der Hut des Mannes im Bild?” den Prozess, den Mann zu finden, den Hut zu erkennen und die Farbe zu bestimmen.
Bildunterschriftenerstellung (Image Captioning): Automatische Erzeugung von Texten zur Beschreibung eines Bildes. Es ist notwendig, den Inhalt des Bildes genau zu erfassen und ihn in eine natürliche Sprache zu übersetzen.
Multimodale Sentimentanalyse: Bestimmung der Stimmung eines Benutzers durch die Kombination von Text, Stimme, Mimik usw. Es ist möglich, ironische Tonlagen oder subtile emotionale Veränderungen, die allein aus dem Text nicht ersichtlich sind, über Änderungen in der Stimmlage oder im Gesichtsausdruck zu erkennen.
Autonome Fahrzeuge: Kombination von Bildern (visuelle Daten), Lidar-Daten, Radar-Informationen und anderen Sensordaten zur sicheren Navigation und Steuerung des Fahrzeugs. Jede Datenquelle bietet einzigartige Informationen, die zusammen eine vollständigere Umgebungswahrnehmung ermöglichen.
Medizinische Diagnostik: Integration von Röntgenbildern, MRIs (Bilder), Patientenakten (Text), biologischen Signalen (zeitliche Daten) und genetischen Informationen zur Diagnose und Vorhersage von Krankheiten. Jede Art von Daten liefert unterschiedliche Hinweise auf eine Krankheit, die zusammen umfassend analysiert werden müssen, um eine präzise Diagnose zu stellen.
Die Forschung zum multimodalen Deep Learning ist eine faszinierende Reise, die die Evolution der Deep-Learning-DNA zeigt. Diese Reise kann in folgende wichtige Phasen unterteilt werden:
In den frühen 2010er Jahren konzentrierten sich die ersten Studien im Bereich des multimodalen Deep Learnings hauptsächlich auf Bildunterschriftenerstellung (image captioning) und VQA (Visual Question Answering). Zu dieser Zeit dominierten CNN-RNN-basierte Modelle, bei denen CNNs (Convolutional Neural Networks) verwendet wurden, um Merkmale aus Bildern zu extrahieren, und RNNs (Recurrent Neural Networks), um Text zu verarbeiten. CNNs waren effektiv darin, räumliche Merkmale von Bildern zu erfassen, während RNNs in der Verarbeitung sequenzieller Informationen stark waren. Aber die frühen Modelle nutzten hauptsächlich das late fusion Verfahren, bei dem jede Modalität unabhängig verarbeitet und die Ergebnisse erst in einem finalen Schritt kombiniert wurden. Diese Methode hatte den Vorteil, dass sie die einzigartigen Eigenschaften jeder Modalität bewahren konnte, jedoch hatte sie die Nachteile, dass sie die Wechselwirkungen zwischen Modalitäten in frühen Phasen nicht ausreichend abbilden konnte.
Einige der bedeutenden Modelle dieser Zeit sind DeViSE (Frome et al., 2013), das Bilder und Wort-Embeddings in den gleichen Raum projiziert, um die Ähnlichkeit zwischen Bildern und Text zu berechnen, und m-RNN (Mao et al., 2014), das CNNs und RNNs kombiniert, um eine Schicht für multimodale Informationssynthese hinzuzufügen.
In der Mitte der 2010er Jahre führte die Einführung des Attention Mechanismus zu einem wichtigen Wendepunkt in der Forschung zum multimodalen Deep Learning. Der Attention Mechanismus ermöglichte es, die Relevanz zwischen Bildern und Text viel präziser zu modellieren. Zum Beispiel erlaubte Attention im Kontext von Bildunterschriften das Lernen, auf welche Bereiche des Bildes beim Erzeugen bestimmter Wörter “geachtet” werden sollte, und bei VQA half es dabei, zu entscheiden, welche Teile eines Bildes betrachtet werden müssen, um eine Frage zu beantworten.
Die Einführung von Attention verbesserte die Leistung von Modellen zur Bildunterschriftenerzeugung und VQA erheblich. Beispiele für bedeutende Modelle sind Show, Attend and Tell (Xu et al., 2015), das Attention einsetzt, um auf Bereiche des Bildes zu fokussieren, die mit den generierten Wörtern relevant sind, und Stacked Attention Networks (Yang et al., 2016), das mehrfach Attention anwendet, um Antworten in VQA aus der Sicht von Fragen zu generieren.
Mit der Einführung der Transformer-Architektur im Jahr 2017 durch den Artikel “Attention is All You Need” erreichte das multimodale Deep Learning eine neue Phase. Der Transformer nutzt das Selbst-Attention-Mechanismus, um die Beziehungen zwischen allen Elementen einer Eingabesequenz direkt zu modellieren.
ViT (Vision Transformer, 2020): Indem ViT Bilder in Patches aufteilt und diese dem Transformer als Eingabe zuführt, ist es zu einem starken Alternativen zu CNNs im Bereich der Bildverarbeitung geworden. ViT modelliert effektiv die langfristigen Abhängigkeiten (long-range dependency) innerhalb von Bildern und zeigt ausgezeichnete Leistungen in verschiedenen Aufgaben wie Bildklassifizierung.
CLIP (Contrastive Language-Image Pre-training, 2021): CLIP lernt, Bilder und Text in den gleichen Raum zu embedden, indem es große Mengen an Bild-Text-Paar-Daten verwendet. Dadurch konnte es ohne zusätzliche Feinabstimmung (fine-tuning) in verschiedenen Downstream-Aufgaben (wie Bildklassifizierung und Objekterkennung) erstaunlich gute Leistungen bei zero-shot-Anwendungen zeigen.
DALL-E (2021), Imagen (2022), Stable Diffusion (2022): Modelle, die hochwertige Bilder basierend auf textbasierten Beschreibungen erzeugen, haben die bemerkenswerte Fähigkeit von Transformer-basierten Generativen Modellen gezeigt. Sie lernen komplexe Beziehungen zwischen Text und Bildern und erzielen Ergebnisse im Bereich der Bilddarstellung, die bislang kaum vorstellbar waren.
GPT-4V (2023), Gemini (2023): Die Einführung großer multimodaler Modelle (LMM, Large Multimodal Model), die Text und Bilder gleichzeitig verstehen und verarbeiten können, hat neue Möglichkeiten für multimodales Deep Learning eröffnet. Diese riesigen Modelle mit Milliarden von Parametern erreichen in verschiedenen multimodalen Aufgaben menschliche Leistungsniveaus und stehen an der Frontlinie der künstlichen Intelligenzforschung.
Die jüngsten Forschungen im Bereich multimodales Deep Learning gehen darüber hinaus, Informationen einfach zu fusionieren. Sie verbessern die Fähigkeit, auf Basis der Informationen aus jeder Modalität neues Wissen zu generieren und zu schließen.
Entwicklung von LMM (Large Multimodal Model): Es erscheinen ständig fortschrittlichere LMM, die mehr Modalitäten (Audio, Video, 3D-Sensordaten usw.) integrieren und komplexere Schließleistungen aufweisen.
Forschung zu effizienten Fusionstechniken: Andererseits wird aktiv an Forschung gearbeitet, um die Effektivität von multimodalen Modellen auch bei begrenzten Rechenressourcen durch Minimierung der Berechnungskosten und Maximierung des Fusionseffekts zu steigern.
Erklärbarkeit (XAI) und ethische Fragen: Mit der Zunahme an Komplexität multimodaler Modelle wird die Bedeutung von Forschungen, die das Verständnis des Entscheidungsprozesses der Modelle fördern und ethische Probleme wie Biased-heit adressieren, größer.
Im nächsten Abschnitt werden wir uns näher mit den frühen Ansätzen im Bereich multimodales Deep Learning und den wichtigen Architekturen, die sich in diesem Prozess durchgesetzt haben, befassen.
Wie in Abschnitt 10.1.3 dargestellt, haben Transformer und CLIP eine Innovation im Bereich des multimodalen Deep Learnings gebracht. Allerdings wurden diese Fortschritte nicht über Nacht erreicht. Schon zuvor gab es zahlreiche Versuche, Bilder und Texte, ja sogar verschiedene Modalitäten miteinander zu kombinieren, und diese frühen Forschungen legten den Grundstein für das moderne multimodale Deep Learning. In diesem Abschnitt werden wir die wichtigsten Ansätze und ihre Bedeutung im frühen Stadium der deep-learning-basierten multimodalen Forschung in den frühen bis mittleren 2010er Jahren untersuchen.
Bildunterschriftgenerierung (Image Captioning) ist die Aufgabe, automatisch einen natürlichsprachlichen Satz (Unterschrift) zu generieren, der ein gegebenes Bild beschreibt. Dies ist ein typisches multimodales Problem, das visuelle Informationen (das Bild) in sprachliche Informationen (den Text) umwandelt und es war einer der Hauptforschungsschwerpunkte im frühen Stadium des deep-learning-basierten multimodalen Deep Learnings. Bildunterschriftgenerierung ähnelt dem Vorgang, bei dem ein kleines Kind ein Bilderbuch betrachtet und sagt: “Hier gibt es einen Hund, und dort gibt es einen Ball!”
In den Anfängen der Bildunterschriftgenerierungsforschung dominierten Modelle, die CNNs und RNNs kombinierten. Es war, als würden zwei Hemisphären eines deep-learning-basierten Gehirns verbunden: ein CNN, das für visuelle Aufgaben zuständig ist, und ein RNN, das für sprachliche Aufgaben verantwortlich ist. Das CNN diente als Bildencoder und extrahierte Merkmalsvektoren aus dem Bild mit Modellen wie VGGNet oder AlexNet, während das RNN als Textdecoder fungierte und Modelle wie LSTM verwendete, um auf Basis der Merkmalsvektoren des Bildes die Unterschriftsatz zu generieren.
Ein repräsentatives Modell ist Show and Tell (Vinyals et al., 2015), welches vorschlug, den durch das CNN extrahierten Bildmerkmalen als Anfangszustand der LSTM-Einheit zu dienen, um die Unterschrift in einem end-to-end-Verfahren zu generieren. Allerdings hatten diese CNN-RNN-Strukturen den Nachteil, dass sie zwar den allgemeinen Inhalt des Bildes gut erfassen konnten, aber die spezifischen Bereiche des Bildes und bestimmte Wörter im Text nicht präzise modellieren konnten.
Der Einführung von Aufmerksamkeitsmechanismen, die bestimmte Bereiche eines Bildes in den Fokus nehmen, folgte eine erhebliche Verbesserung. Dieser Ansatz ermöglichte es Modellen, bei der Generierung jedes Worts einer Unterschrift zu lernen, auf welche Regionen des Bildes sie sich konzentrieren sollten, um genauer und detailliertere Beschreibungen zu produzieren.
Show, Attend and Tell (Xu et al., 2015) war das erste Modell, das den Soft-Aufmerksamkeitsmechanismus in die Bildunterschriftgenerierung einführte. Es lernte bei der Generierung jedes Worts der Unterschrift, welche Regionen des Bildes zu beachten sind, um genauer und detailliertere Beschreibungen zu erstellen.
Ab 2017 kam es zur Einführung von Ansätzen, die sowohl den gesamten Kontext des Bildes (top-down) als auch spezifische Objekte (bottom-up) nutzen. Die bottom-up-Methode verwendet Modelle wie Faster R-CNN, um wichtige Objekte im Bild zu identifizieren, während die top-down-Methode während des Prozesses der Unterschriftgenerierung die Aufmerksamkeitsgewichte dieser Objektmerkmale berechnet.
Das Bottom-Up and Top-Down Attention Modell (Anderson et al., 2018) kombinierte diese beiden Ansätze und führte zu einer erheblichen Verbesserung der Leistung bei der Bildunterschriftgenerierung. Dies ist vergleichbar mit dem Prozess, die allgemeine Handlungslinie eines Geschichtsverlaufs zu berücksichtigen, während man die spezifischen Objekte in jeder Szene detailliert beschreibt.
Bildunterschrift-Forschung hat wichtige Elemente zum Deep-Learning-DNA hinzugefügt. Die Kombination von CNN-RNN bot ein grundlegendes Gerüst, um verschiedene Modalitäten effektiv zu kombinieren, und die Aufmerksamkeitsmechanismen wurden zu einem zentralen Technologieelement im multimodalen Deep Learning. Darüber hinaus hat Bottom-Up and Top-Down Attention die Fähigkeit der Deep-Learning-Modelle zur Bildverstehens auf ein neues Niveau gehoben.
Diese Fortschritte legten den Grundstein für eine Erweiterung über die Bildunterschrift-Erstellung hinaus zu verschiedenen multimodalen Aufgaben wie VQA und multimodal maschinelles Übersetzen. In jüngerer Zeit haben transformer-basierte Modelle wie BLIP das Potenzial gezeigt, nicht nur in der Bildunterschrift-Erstellung, sondern auch in einer Vielzahl von multimodalen Aufgaben gute Leistungen zu erzielen.
BLIP (Bootstrapping Language-Image Pre-training) ist ein transformer-basiertes Modell zur Erstellung von Bildunterschriften. BLIP lernt Bilder und Texte gemeinsam vor, um in der Bildunterschrift-Erstellung sowie bei VQA und Bild-Text-Suche verschiedene multimodale Aufgaben gut zu bewältigen.
Das folgende Beispiel zeigt, wie man mit der Hugging Face Transformers-Bibliothek ein Bilduntertitelung-Modell (BLIP) verwendet.
# !pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
import requests
import matplotlib.pyplot as plt
# Load the model and processor
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# Download the image
url = "http://images.cocodataset.org/val2017/000000000632.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# Display the image
plt.imshow(image)
plt.axis('off')
plt.show()
# Preprocess the input
inputs = processor(image, return_tensors="pt")
# Generate the caption
outputs = model.generate(**inputs)
# Decode and print the caption
caption = processor.decode(outputs[0], skip_special_tokens=True)
print("Generated caption:", caption)
Generated caption: a bedroom with a bed and a windowVisuelle Frage- und Antwortaufgaben (Visual Question Answering, VQA) beinhalten die Aufgabe, auf einer gegebenen natürlichsprachlichen Frage basierend auf den Inhalt eines Bildes eine Antwort zu generieren. Während Bildbeschreibungen (Image Captioning) sich darauf konzentrieren, den Inhalt eines Bildes zu “beschreiben”, geht es bei VQA darum, mit dem Bild “Fragen und Antworten” zu führen. Ein Beispiel wäre die Beantwortung der Frage: “Was isst die Katze?”. VQA erfordert eine komplexere und anspruchsvollere Fähigkeit zur Verstehens von Bildern als Bildbeschreibungen, insbesondere in Bezug auf das Verständnis und Schließen von Zusammenhängen zwischen Bildern und Fragen (Text).
Ähnlich wie bei Bildbeschreibungen nutzten die frühen VQA-Modelle eine Kombination aus CNNs und RNNS. Dabei wurden mit CNNs die Bildmerkmale extrahiert und mit RNNs die Fragen kodiert, um diese beiden Merkmale zu kombinieren und Antworten zu generieren. Allerdings war es schwierig, komplexe Fragen allein durch das einfache Kombinieren von Bild- und Frage-Merkmalsinformationen zu beantworten.
Nachdem Aufmerksamkeitsmechanismen in der Bildbeschreibung erfolgreich waren, wurden sie auch für VQA eingeführt. Co-Aufmerksamkeit (Co-Attention) wendet Aufmerksamkeit sowohl auf das Bild als auch auf die Frage an, um die Relevanz zwischen den Wörtern der Frage und den Bereichen des Bildes zu berechnen. Dies ermöglicht es, relevante Bereiche des Bildes in Bezug auf die Frage genauer zu identifizieren.
Stacked Attention wiederholt den Aufmerksamkeitsprozess mehrfach, um die komplexen Beziehungen zwischen Bild und Frage schrittweise zu erfassen. Dies ähnelt einem Detektiv, der ein Foto mehrmals überprüft, um die Relevanz für eine Frage allmählich tiefer zu verstehen.
Beispiele für solche Modelle sind Stacked Attention Networks (SAN) (Yang et al., 2016) und Dual Attention Networks (DAN) (Nam et al., 2017). SAN wendet mehrfach Aufmerksamkeit auf das Bild an, um eine Antwort auf die Frage zu generieren, während DAN die Aufmerksamkeit für Bild und Frage getrennt berechnet und diese dann kombiniert, um eine Antwort zu erzeugen.
Ein wesentlicher Unterschied zwischen Bildbeschreibung und VQA ist die Integration externer Kenntnisse. Um die Inferenzfähigkeit von VQA-Modellen weiter zu verbessern, wurden Studien durchgeführt, die externe Kenntnisse (Allgemeinwissen, Enzyklopädiekenntnisse usw.) nutzten. Knowledge Base (KB) ermöglichten es Modellen, auf externen Informationen zurückzugreifen, um Antworten zu generieren. Dies stellte jedoch auch Herausforderungen dar, wie die Relevanz von Kenntnissen und die Komplexität des Inferenzprozesses.
VQA-Forschung hat wichtige Gene zur Deep-Learning-DNA hinzugefügt. Die Kombination von CNNs und RNNs bildet die grundlegende Struktur für die Integration von Bildern und Text, die sie mit Bildbeschreibungen teilt. Multimodale Aufmerksamkeit verlieh Deep-Learning-Modellen die Fähigkeit, komplexe Beziehungen zwischen Bildern und Fragen zu modellieren. Dies bedeutet, dass diese Modelle nicht nur Informationen kombinieren können, sondern auch ihre Wechselwirkung verstehen und daraus Schlussfolgerungen ziehen.
Die Integration externer Kenntnisse öffnete die Möglichkeit, dass Deep-Learning-Modelle durch die Nutzung von externen Wissen zu einem höheren Grad der Inferenz fähig sind. Dies zeigt, dass diese Modelle nicht nur auf Daten angewiesen sind, sondern auch menschliches Wissen und Erfahrung nutzen können. 10.2.1 und 10.2.2 haben gezeigt, dass Bildunterschriftenerstellung (Image Captioning) und Visuelle Fragebeantwortung (VQA) zwei zentrale Aspekte der frühen multimodalen Deep Learning-Forschung waren. Diese Studien leisteten einen bedeutenden Beitrag zur Anwendung und Weiterentwicklung von Kern-Deep-Learning-Technologien wie CNNs, RNNs und Aufmerksamkeitsmechanismen auf multimodale Probleme und bildeten die Grundlage für das Erscheinen noch stärkerer multimodaler Modelle basierend auf dem Transformer (wie CLIP, DALL-E, GPT-4V, Gemini usw.).
In jüngerer Zeit haben sich transformerbasierte VQA-Modelle wie ViLT (Vision-and-Language Transformer) etabliert und gute Leistungen gezeigt. ViLT führt Bild-Patches und Texttokens in dasselbe Transformationsmodell ein, um die komplexen Interaktionen zwischen Bildern und Text effektiv zu modellieren.
ViLT (Vision-and-Language Transformer) ist eines der prominentesten transformerbasierten VQA-Modelle. ViLT führt Bild-Patches und Texttokens in dasselbe Transformationsmodell ein, um die komplexen Interaktionen zwischen Bildern und Text effektiv zu modellieren.
Das folgende Beispielcode zeigt, wie man mit der Hugging Face Transformers-Bibliothek VQA mit dem ViLT-Modell durchführt.
from transformers import ViltProcessor, ViltForQuestionAnswering
from PIL import Image
import requests
import matplotlib.pyplot as plt
# 모델과 프로세서 로드
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
model = ViltForQuestionAnswering.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
# 이미지 다운로드
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# 이미지 출력
plt.imshow(image)
plt.axis('off') # 축 제거
plt.show()
# 질문 설정
question = "How many cats are in the image?"
print("Question:", question)
# 입력 전처리
encoding = processor(image, question, return_tensors="pt")
# 추론
outputs = model(**encoding)
logits = outputs.logits
idx = logits.argmax(-1).item()
print("Predicted answer:", model.config.id2label[idx])
Question: How many cats are in the image?
Predicted answer: 2Angenommen, wir haben zwei Arten von Informationen: Bilder und Text. Wie können diese beiden Informationen kombiniert werden? Die einfachste Methode besteht darin, den Textvektor an den Bildvektor anzuhängen, um einen neuen Vektor zu bilden. Das Verknüpfen von Informationen aus heterogenen Datenquellen wird als Fusion bezeichnet. Die effiziente Fusion von Informationen aus zwei heterogenen Datensätzen ist der Kernpunkt des Multimodalen Lernens. Ein Grund, warum es schwierig sein kann, mit multimodalem Deep Learning zu beginnen, liegt darin, dass es sich um ein sehr schnell wachsendes Feld handelt, in dem eine systematische Zusammenfassung fehlt.
In diesem Abschnitt werde ich die Methoden der Multimodalen Fusion auf Basis des Kurses “Multimodal Machine Learning” von Carnegie Mellon University (CMU) in drei Hauptkategorien unterteilen. Diese Klassifizierung ist zwar nicht standardmäßig im aktuellen multimodalen Forschungsbereich, aber sie ist sehr nützlich für ein systematisches Verständnis der verschiedenen Fusionstechniken.
Joint Representations beziehen sich auf die Darstellung von Daten aus mehreren Modalitäten in einem gemeinsamen Vektorraum (vector space). Es ist, als ob Text und Bild zusammen auf einer Leinwand gezeichnet werden.
Anstatt die Daten jeder Modality getrennt zu verarbeiten, werden sie zu einem integrierten Merkmalsvektor (feature vector) fusioniert. Dieser Vektor fasst die Informationen der Modalitäten zusammen. So kann das Modell tiefere Korrelationen zwischen den Modalitäten lernen. Ein einzelnes Modell kann mehrere Modalitäten verarbeiten, und da die Informationen aus mehreren Modalitäten in einen einzigen Vektor komprimiert werden, ist die Modellstruktur relativ einfach und effizient. Allerdings können die einzigartigen Merkmale jeder Modality während des Fusionierungsprozesses verdünnt oder verloren gehen. Wenn eine bestimmte Modality mehr Informationen als andere enthält, kann dies zu einem Informationsungleichgewicht führen. Darüber hinaus ist es eine sehr schwierige Aufgabe, Daten aus verschiedenen Modalitäten in einen sinnvollen Vektor zusammenzuführen.
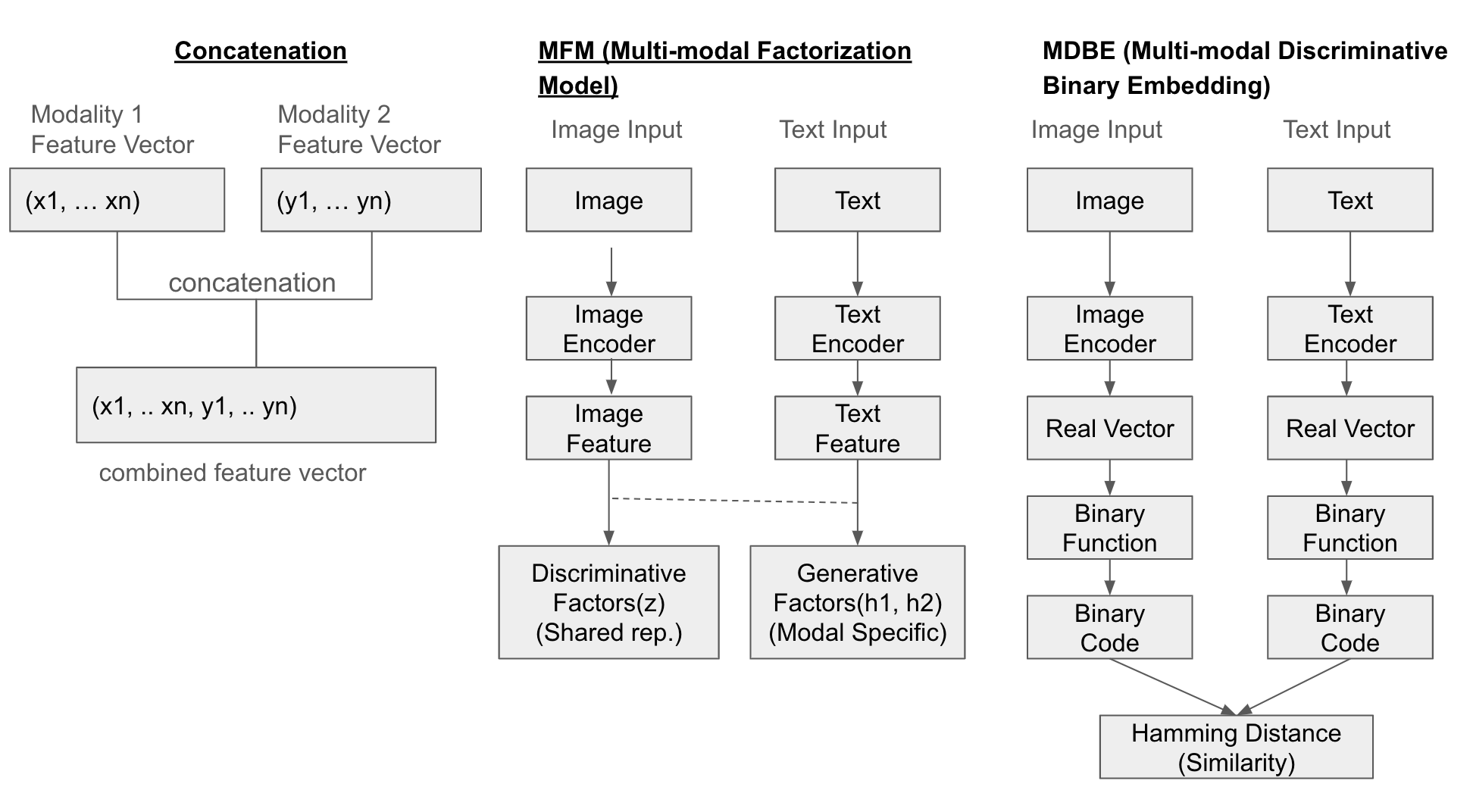
Die einfachste Methode besteht darin, die Merkmalsvektoren jeder Modality direkt anzuhängen (concatenate). Neben dieser gibt es noch das Multi-modal Factorization Model (MFM), das verschiedene Aspekte von Daten durch Matrixfaktorisierung kombiniert, um einen gemeinsamen Darstellungsraum zu erstellen. Das Multi-modal Discriminative Binary Embedding (MDBE) ist eine Methode, die multimodale Daten wie Bilder und Text in binäre Codes übersetzt.
In jüngster Zeit wurden Methoden wie COSA (Concatenated Sample) vorgeschlagen, bei denen mehrere Bild-Text-Paare sequentiell verknüpft werden und ein transformer-basierter Modell angewendet wird, um visuelle Inhalte und zeitliche Anhaltspunkte gemeinsam zu lernen. Zudem verwendet Attentional Concatenation eine mehrstufige Struktur zur Generierung hochauflösender Bilder aus Text, bei der die Ergebnisse von vorherigen Layern als Eingabe für nachfolgende Layern genutzt werden.
Strukturbeschreibung
Die folgende Abbildung veranschaulicht die Fusion in drei Methoden (Concatenation, MFM, MDBF).
Beispiel
from transformers import AutoModel, AutoProcessor, AutoTokenizer
from PIL import Image
import torch
import requests
import matplotlib.pyplot as plt
# Load pre-trained models and processor/tokenizer for image and text
image_model_name = "google/vit-base-patch16-224-in21k" # ViT (Vision Transformer)
text_model_name = "bert-base-uncased" # BERT
image_processor = AutoProcessor.from_pretrained(image_model_name)
image_model = AutoModel.from_pretrained(image_model_name)
tokenizer = AutoTokenizer.from_pretrained(text_model_name)
text_model = AutoModel.from_pretrained(text_model_name)
# Example image and text
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "Two cats sleeping on a couch."
# Display the image
plt.imshow(image)
plt.axis('off') # Remove axes
plt.show()
# Preprocess image and text
image_inputs = image_processor(images=image, return_tensors="pt")
text_inputs = tokenizer(text, return_tensors="pt")
# Feature extraction (embeddings) for each modality
with torch.no_grad(): # Disable gradient calculation (inference mode)
image_features = image_model(**image_inputs).last_hidden_state[:, 0, :] # [CLS] token embedding
text_features = text_model(**text_inputs).last_hidden_state[:, 0, :] # [CLS] token embedding
# Create Joint Representation (Concatenation)
joint_representation = torch.cat((image_features, text_features), dim=1)
print("Image Features Shape:", image_features.shape) # Image feature vector size
print("Text Features Shape:", text_features.shape) # Text feature vector size
print("Joint Representation Shape:", joint_representation.shape) # Combined feature vector size (image + text)Fast image processor class <class 'transformers.models.vit.image_processing_vit_fast.ViTImageProcessorFast'> is available for this model. Using slow image processor class. To use the fast image processor class set `use_fast=True`.
Image Features Shape: torch.Size([1, 768])
Text Features Shape: torch.Size([1, 768])
Joint Representation Shape: torch.Size([1, 1536])Koordinierte Darstellungen sind eine Methode, bei der jede Modalität in einem separaten Raum dargestellt wird, wobei die Beziehungen zwischen ihnen explizit gelernt werden. Es ist ähnlich wie das Zeichnen mehrerer Leinwände so, dass jede Leinwand harmonisch zueinander passt.
Jede Modalität wird durch einen separaten Merkmalsvektor dargestellt, aber diese Vektoren werden so trainiert, dass sie sich gegenseitig “koordinieren”. Das bedeutet, jeder Merkmalsraum der Modalitäten ist unabhängig, aber ihre Ähnlichkeiten, Reihenfolgen und andere Beziehungen werden gelernt, um sinnvolle Verbindungen zwischen ihnen herzustellen. Ein Vorteil dieses Ansatzes besteht darin, dass die einzigartigen Merkmale jeder Modalität maximiert erhalten bleiben, während gleichzeitig ihre Beziehung zu anderen Modalitäten berücksichtigt wird. Darüber hinaus kann er verschiedene Formen von Beziehungen zwischen unterschiedlichen Modalitäten lernen und daher auf eine Vielzahl von multimodalen Problemen angewendet werden.
Allerdings kann die getrennte Verarbeitung jeder Modalität dazu führen, dass die Modellstruktur komplexer wird als bei gemeinsamen Darstellungen. Dies kann das Design und die Training des Modells erschweren. Zudem ist es eine schwierige Aufgabe, die Beziehungen zwischen den verschiedenen Modalitäten explizit zu lernen.
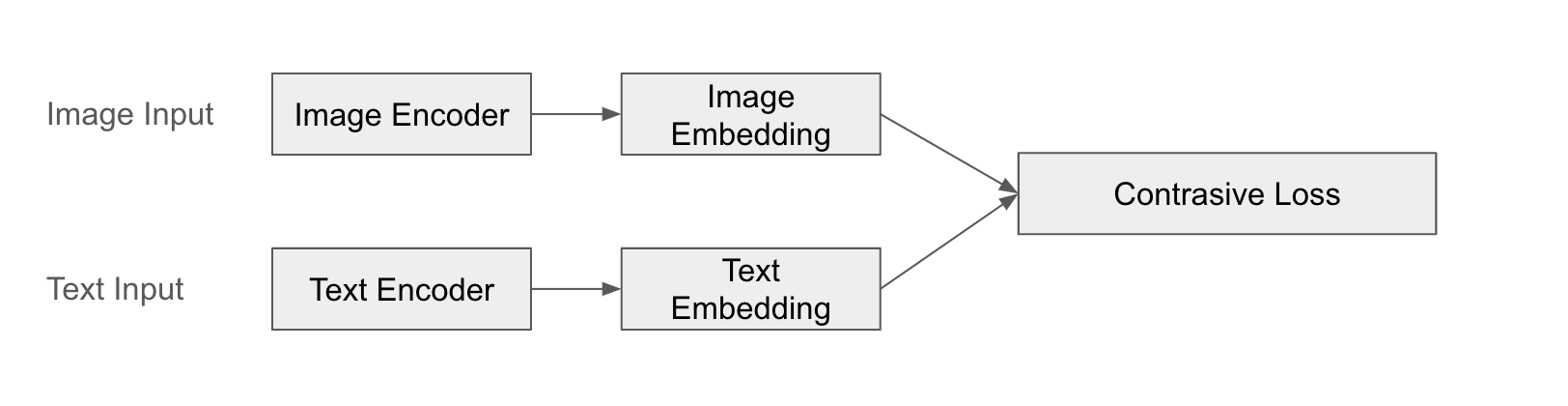
Ein prominentes Beispiel dafür ist CLIP (Contrastive Language-Image Pre-training). CLIP verarbeitet Bilder und Texte jeweils mit separaten Encodern, um Merkmalsvektoren zu erhalten, und lernt dann die Ähnlichkeiten zwischen ihnen. CLIP wird so trainiert, dass Bild und Text “zusammenpassen”, um eine sinnvolle Beziehung zwischen Bild und Text herzustellen.
Der Erfolg von CLIP zeigt sich besonders in der zero-shot Lernfähigkeit. Das vortrainierte CLIP-Modell kann neue Bilder klassifizieren oder suchen, ohne zusätzliche Training für spezifische Aufgaben zu benötigen. Dies ist möglich, weil es die semantischen Verbindungen zwischen Text und Bild effektiv gelernt hat.
Strukturbeispiel
Das folgende Diagramm veranschaulicht die Fusion von CLIP:
Beispiel
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import torch
import requests
import matplotlib.pyplot as plt
# Load CLIP model and processor
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Example image and text
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "Two cats sleeping on a couch."
# Display image
plt.imshow(image)
plt.axis('off') # Remove axes
plt.show()
# Preprocess image and text
inputs = processor(text=[text], images=image, return_tensors="pt", padding=True)
# Extract image and text features (embeddings)
with torch.no_grad():
outputs = model(**inputs)
image_features = outputs.image_embeds
text_features = outputs.text_embeds
# Coordinated Representation: Keep features of each modality separate
print("Image Features Shape:", image_features.shape)
print("Text Features Shape:", text_features.shape)
# Calculate similarity between image and text (dot product)
similarity = torch.matmul(image_features, text_features.T) # Or text_features @ image_features.T
print("Image-Text Similarity:", similarity.item())
Image Features Shape: torch.Size([1, 512])
Text Features Shape: torch.Size([1, 512])
Image-Text Similarity: 0.29803216457366943Die obige Methode kann wie folgt angewendet werden, um einen einfachen Zero-Shot-Test durchzuführen.
# Zero-shot 이미지 분류
# - 여러 텍스트 후보군을 만들고, 각 텍스트와 이미지 간의 유사도를 계산하여 가장 높은 유사도를 갖는 텍스트를 선택
candidate_texts = ["a photo of a cat", "a photo of a dog", "a photo of a bird"]
inputs = processor(text=candidate_texts, images=image, return_tensors="pt", padding=True)
with torch.no_grad():
outputs = model(**inputs)
image_features = outputs.image_embeds
text_features = outputs.text_embeds
logits_per_image = outputs.logits_per_image # 유사도 점수
probs = logits_per_image.softmax(dim=1) # 확률
predicted_class_idx = probs.argmax().item()
predicted_class = candidate_texts[predicted_class_idx]
print("Predicted Class:", predicted_class)
print("Probabilities:", probs)Predicted Class: a photo of a cat
Probabilities: tensor([[9.9403e-01, 5.1377e-03, 8.3070e-04]])Encoder-Decoder ist eine Methode, die Daten einer Modalität in Daten einer anderen Modalität umwandelt. Sie wird häufig bei der Sprachübersetzung verwendet.
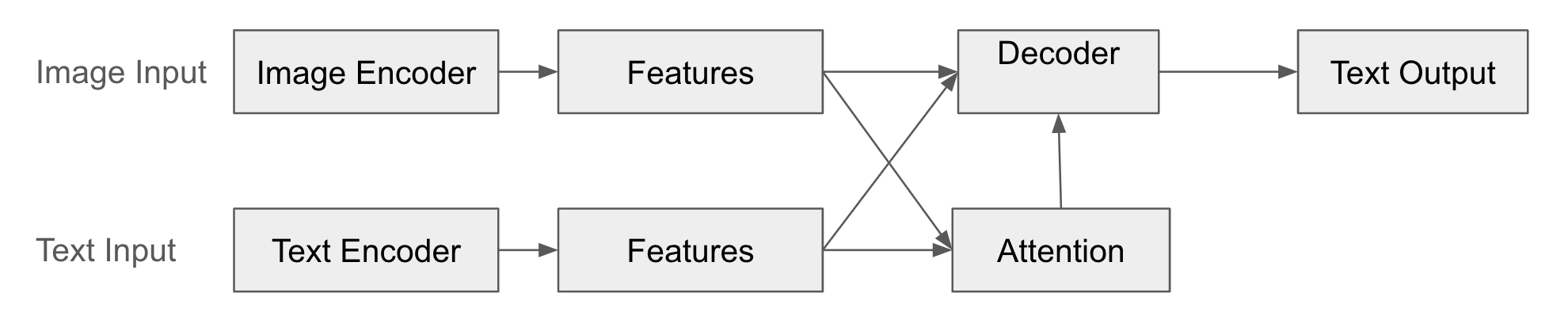
In dieser Struktur verwandelt der Encoder (der Eingabepfad) die Daten der Eingangsmodalität (z.B. Bilder) in Merkmalsvektoren. Diese Merkmalsvektoren komprimieren die wesentlichen Informationen der Eingangsdaten. Der Decoder (der Ausgabepfad) generiert auf Basis des von dem Encoder erstellten Merkmalsvektors Daten einer anderen Modalität (z.B. Text). Der Decoder “interpretiert” die Ausgabe des Encoders und erzeugt neue Formate von Daten. Darüber hinaus lernt der Decoder durch den Aufmerksamkeitsmechanismus, auf welche Teile des Merkmalsvektors des Encoders er bei der Generierung der Ausgabedaten “achten” sollte.
Ein Vorteil dieser Methode ist ihre Anwendbarkeit in verschiedenen Aufgaben, die unterschiedliche Formen von Daten verbinden, wie zum Beispiel Bildunterschriftenerstellung, VQA (Visuelle Fragebeantwortung) und maschinelles Übersetzen. Sie kann auch angewendet werden, wenn die Eingangs- und Ausgabemodalitäten sich unterscheiden; verschiedene Kombinationen sind möglich, wie Text-Bild, Bild-Text oder Audio-Text.
Ein typisches Beispiel hierfür sind die Bildunterschriftenerstellung und VQA (Visuelle Fragebeantwortung). Bei der Bildunterschriftenerstellung werden Bilder durch den Encoder verarbeitet, um Merkmalsvektoren zu erhalten, und dann wird ein Decoder verwendet, um eine Bildunterschrift (Text) zu generieren. Bei VQA werden das Bild und die Frage (Text) jeweils durch einen Encoder verarbeitet, und der Aufmerksamkeitsmechanismus wird verwendet, um die Relevanz zwischen dem Bild und der Frage festzustellen; anschließend wird ein Decoder verwendet, um eine Antwort (Text) zu generieren.
Bei langen Eingangs- oder Ausgabedaten kann jedoch Informationsverlust auftreten oder der Berechnungsaufwand zunehmen. Insbesondere bei RNN-basierten Modellen kann das Verschwinden des Gradienten (gradient vanishing problem) es erschweren, langfristige Abhängigkeiten zu lernen. Darüber hinaus muss Encoder und Decoder gleichzeitig trainiert werden, was zu Instabilität oder Schwierigkeiten beim Training führen kann.
Strukturbeispiel
Das folgende Diagramm illustriert die Fusion von Encoder-Decoder.
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
import requests
import matplotlib.pyplot as plt
# Load model and processor
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# Download image
url = "http://images.cocodataset.org/val2017/000000000139.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# Display image
plt.imshow(image)
plt.axis('off')
plt.show()
# Input text (optional - Conditional Generation)
# text = "describe this image:" # Prompt (guide image description)
text = "a photo of"
# Preprocess image and text (optional)
# If text is provided, it uses the text as a prompt to generate the caption.
inputs = processor(image, text=text, return_tensors="pt")
# Generate caption
outputs = model.generate(**inputs)
# Decode and print caption
caption = processor.decode(outputs[0], skip_special_tokens=True)
print("Generated caption:", caption)
Generated caption: a photo of a living room with a television and a fireplaceDieses Beispiel zeigt das Bildunterschriftgenerieren, ein typisches Beispiel für die Struktur von Encoder-Decoder. Der Encoder nimmt ein Bild (visueller Encoder von BLIP) als Eingabe und extrahiert Merkmalsvektoren. Der Decoder erzeugt Text (Textdecoder von BLIP). Durch den Aufmerksamkeitsmechanismus wird während der Erstellung der Bildunterschrift bestimmt, auf welche Teile des Merkmalsvektors geachtet werden soll. Man kann Prompts festlegen, die die durch Text generierten Bildunterschriften beeinflussen. BLIP kann sowohl Bilder als auch Text als Eingabe verwenden, hier wird jedoch nur das Bild als Eingabe verwendet und der Text wird vom Decoder erzeugt.
In den Abschnitten 10.3.1, 10.3.2 und 10.3.3 wurden die drei Kerntheorien der multimodalen Fusion, nämlich Gemeinsame Repräsentationen, Koordinierte Repräsentationen und Encoder-Decoder, untersucht. Jede Methode hat ihre eigenen Merkmale und Vor- und Nachteile, daher ist es wichtig, je nach Anwendungsbereich die geeignete Methode auszuwählen.
In der multimodalen Deep Learning ist “Fusion” ein zentrales Verfahren, um Informationen aus verschiedenen Modalitäten zu kombinieren, um reichhaltigere und stärkere Darstellungen zu erstellen. In Abschnitt 10.3 wurde kurz die Fusionstheorie auf der Grundlage von CMU-Vorlesungen betrachtet, aber die tatsächliche multimodale Fusionforschung hat sich viel vielfältiger und dynamischer entwickelt. In dieser Tiefenanalyse werden wir verschiedene Klassifizierungssysteme für Fusion und aktuelle Forschungstrends detailliert analysieren und uns anschauen, welche Technologien im Jahr 2025 in den Fokus geraten.
Die multimodale Fusion kann nicht nur anhand eines einzigen Kriteriums klassifiziert werden. Forscher klassifizieren die Fusionstechniken aus verschiedenen Perspektiven, und jede Klassifizierung ist nicht ausschließlich, sondern ergänzt sich gegenseitig.
Diese Klassifizierung konzentriert sich auf den “Zeitpunkt” in multimodalen Deep Learning-Modellen, zu dem die Fusion stattfindet. (Siehe Abschnitt 10.3.4)
Early Fusion (Frühe Fusion): Die “rohen” Daten (oder sehr früh verarbeiteten Merkmale) jeder Modalität werden auf der Eingabeebene des Modells kombiniert.
Late Fusion (Späte Fusion): Jede Modalität wird durch ein separates Modell verarbeitet, und die Ausgaben der Modelle (z.B. Vorhersageergebnisse) werden in einem letzten Schritt kombiniert.
Hybrid Fusion (Gemischte Fusion): Eine Kombination von Early Fusion und Late Fusion. Die Fusion wird auf verschiedenen Ebenen des Modells durchgeführt, um Informationen auf verschiedenen Ebenen zu nutzen.
Model-Agnostische Fusion: Allgemeine Fusionsmethoden, die nicht von einem bestimmten Modell abhängig sind (Early, Late, Hybrid Fusion usw.).
Modellspezifische Fusion: Fusionsmethoden, die auf spezifischen Modellstrukturen abgestimmt sind.
Neueste Forschung: Bei der CVPR-Workshop (MULA 2025), die am 11. und 12. Juni 2025 stattfinden wird, wird über Modellestrukturen diskutiert, die effektiv verschiedene Sensordaten (Kameras, LiDAR, Radar usw.) im Bereich der autonomen Fahrt integrieren können. Das Ziel dieses Workshops ist es, interdisziplinäre Wechselwirkungen und Kooperationen zwischen den Communities von Computer Vision, Multimedia, Fernerkundung und Robotik zu fördern, wobei insbesondere ein großer Fokus auf multimodale Ansätze im Bereich der autonomen Fahrt gelegt wird.
Symmetrisch (Symmetric) vs. Asymmetrisch (Asymmetric) Fusion:
Symmetrisch: Alle Modalitäten werden gleichwertig behandelt.
Asymmetrisch: Einzelnen Modalitäten wird ein größerer Stellenwert oder andere Rollen zugewiesen.
Neueste Forschung: “Learning Deep Multimodal Feature Representation with Asymmetric Multi-layer Fusion” schlägt einen effektiven Framework vor, um multimodale Merkmale in mehreren Layern innerhalb eines einzelnen Netzwerks zu integrieren. Diese Studie führt zwei Arten von asymmetrischen Fusionsoperationen ein, Channel Shuffle und Pixel Shift, um verschiedene Merkmale abhängig von verschiedenen Fusionsrichtungen zu lernen. Zudem präsentiert “Multimodal sentiment analysis based on multi-layer feature fusion”, das im Januar 2025 veröffentlicht wurde, einen neuen Ansatz für genaue Stimmungsanalyse in Anwesenheit von Modalitätsungleichgewichten und impliziten Ausdrucksbedingungen.
Explizit (Explicit) vs. Implizit (Implicit) Fusion:
Explizit: Beziehungen zwischen Modalitäten werden explizit definiert oder modelliert. (z.B. Aufmerksamkeitsmechanismen)
Implizit: Die Beziehungen zwischen Modalitäten werden nicht direkt definiert, sondern das Modell lernt die Beziehungen durch Lernen selbst zu erkennen. (z.B. einfache Kombination)
Neueste Forschung: Bei der HCI International 2025 Konferenz (Juni 2025) wird eine Studie vorgestellt, die die Vor- und Nachteile von expliziter und impliziter Fusion vergleicht.
Die am meisten beachtete Fusionsmethode in den Forschungen von 2024-2025 ist die aufmerksamkeitsbasierte Mechanismen.
Neueste Forschung
“Bi-Att3DDet”, eine im Januar 2025 veröffentlichte Studie, führt einen bidirektionalen aufmerksamkeitsbasierten Fusionsansatz für die 3D-Objekterkennung bei autonomen Fahrzeugen ein. Diese Forschung schlägt eine bidirektionale Interaktionsmethode vor, um den komplementären Informationsaustausch zwischen LiDAR und Kamerasdaten zu maximieren.
“LANMSFF”, eine Studie, die im März 2024 veröffentlicht und im Februar 2025 überarbeitet wurde, kombiniert ein leichtes aufmerksamkeitsbasiertes Netzwerk mit multi-skalierten Merkmalsfusionen für die Mehrfachansichtsfazialausdruckserkennung. Dieser Ansatz generiert gleichzeitig Channel- und Spatial-Aufmerksamkeitskarten, um wichtige Merkmale hervorzuheben und irrelevante zu unterdrücken.
Neueste Neurowissenschaftsforschungen (2025) untersuchen den Einfluss der Cross-Modalen Kongruenz auf die Verarbeitung und Ablagerung sensorischer Informationen. Diese Studie zeigt, dass die Kongruenz zwischen auditiven und visuellen Reizen eine wichtige Rolle in frühen Stadien der sensorischen Verarbeitung spielt. #### 2.2 Multi-head Attention
Konzept: Durch die Verwendung mehrerer Aufmerksamkeitsköpfe (heads) werden Beziehungen zwischen Modalitäten aus verschiedenen Perspektiven erfasst. Jeder Kopf verwendet unterschiedliche Gewichtsmatrizen (W_Q, W_K, W_V), um die Eingabedaten zu transformieren und die Aufmerksamkeit zu berechnen. Daher kann jeder Kopf sich auf verschiedene Aspekte der Eingabedaten konzentrieren (z.B. Semantik, grammatische Struktur, Stil).
Vorteile: Verschiedene Arten von Beziehungen können gleichzeitig modelliert werden, was das Lernen reichhaltigerer und komplexerer Darstellungen ermöglicht. Zum Beispiel, beim Führen von Bildern und Texten kann ein Kopf sich auf die Beziehung zwischen Objekten in einem Bild und Wörtern im Text konzentrieren, während ein anderer Kopf sich auf die Beziehung zwischen der allgemeinen Stimmung des Bildes und dem Tonfall des Textes fokussiert.
Aktuelle Forschung: Kürzlich haben große multimodale Modelle (LMM) diese Technik weiter ausgebaut und verfeinert, um komplexe Wechselwirkungen zwischen verschiedenen Modalitäten wie Bildern, Texten, Audios und Videos effektiv zu modellieren.
Kontrastives Lernen (Contrastive Learning):
Konzept: Verwandte Modalitätenpaare (z.B. Bild und zugehörige Beschriftung) werden im Einbettungsraum nahe beieinander, unverbundene Paare hingegen weit voneinander entfernt gelernt.
Vorteile: Wirksam auch bei großen Datensätzen ohne Labels, was bei der Lösung von Datenmangelproblemen hilfreich sein kann.
Aktuelle Forschung: “Dual-Level Cross-Modal Contrastive Clustering” (2024) schlägt eine neue Methode des kontrastiven Lernens vor, um die Kluft zwischen visuellen Darstellungen und textueller Bedeutung zu überbrücken.
Maskebasiertes Lernen (Masking-based Learning):
Konzept: Ein Teil der Eingabe wird masiert und das Modell lernt, diese mit Hilfe von Informationen aus einer anderen Modalität wiederherzustellen.
Vorteile: Es kann die gegenseitig komplementären Beziehungen zwischen den Modalitäten lernen. Zum Beispiel, einen Teil eines Bildes zu verdecken und das verdeckte Teil anhand der Textbeschreibung vorherzusagen oder einigen Wörtern in einem Text zu masieren und diese anhand des Bildes vorherzusagen.
Aktuelle Forschung: CAST (2025) hat durch die Masked Node Prediction (MNP)-Prätrainingsstrategie die Ausrichtung von Graphknoten und Texttoken verbessert.
Multimodale Fusion kann auf verschiedene Weisen klassifiziert werden, wobei jede Klassifikation eine andere Perspektive bietet. In der Praxis werden häufig diese Klassifikationen kombiniert verwendet. Zurzeit im Jahr 2025 konzentriert sich die Forschung zur multimodalen Fusion auf die Entwicklung effektiver Fusionstechniken durch das Nutzen von token-basierten feinen Interaktionen, Cross-Attention-Mechanismen und selbstüberwachten Lernmethoden. Insbesondere bei wichtigen wissenschaftlichen Veranstaltungen wie dem CVPR 2025 Workshop (Juni 2025, Nashville) werden aktive Diskussionen über die Fortschritte der multimodalen Fusionstechnologien in verschiedenen Anwendungsbereichen wie autonomes Fahren, medizinische Diagnostik und Materialwissenschaften stattfinden.
Durch diese Deep Dive wird es möglich sein, verschiedene Klassifizierungssysteme der multimodal fusion zu verstehen und die Merkmale jeder Methode zu erkennen, um so eine tiefergehende Analyse der verschiedenen multimodalen Modelle zu ermöglichen, die vorgestellt werden.
Es tut mir leid, aber Sie müssen den zu übersetzenden Koreanischen Text bereitstellen. Bitte geben Sie den Text an, den Sie von Koreanisch ins Deutsche übersetzen lassen möchten.
In den Abschnitten 10.3.1 bis 10.3.3 haben wir uns mit Methoden zur Fusion von multimodalen Daten beschäftigt. Dies ist eine theoretische Klassifikation. Bei der Entwicklung tatsächlicher multimodaler Modelle müssen strategisch welche Fusionsmethode, zu welchem Zeitpunkt und wie sie angewendet wird, anhand der gegebenen Problemstellung und den Eigenschaften der Daten bestimmt werden. In diesem Abschnitt werden wir uns mit fortschrittlichen Modalitätsintegrationsstrategien befassen, die von aktuellen multimodalen Modellen verwendet werden.
Die frühe Fusion kombiniert Eingaben aus mehreren Modalitäten in einem frühen Stadium des Modells. Die einfachste Form besteht darin, die Merkmalsvektoren jeder Modalität zu verketten (concatenate). Der Vorteil der frühen Fusion liegt darin, dass sie es leicht macht, niedrigstufige (low-level) Interaktionen zwischen den Modalitäten zu erfassen. Zum Beispiel, wenn Farben in Bildern und bestimmte Wörter im Text stark miteinander korrelieren, kann die frühe Fusion diese Beziehungen leichter lernen. Allerdings hat sie den Nachteil, dass die Eigenschaften jeder Modalität nicht ausreichend genutzt werden können. Insbesondere, wenn spezialisierte Verarbeitung für jede Modalität erforderlich ist (z.B., CNNs für Bilder und RNNs für Text), kann die frühe Fusion ineffektiv sein.
Neuere Forschungen haben auch Benchmarks vorgestellt, die die Effektivität der frühen Fusion in Umgebungen mit unsicheren multimodalen Daten (noisy data) überprüfen.
Schauen wir uns ein einfaches Beispiel für die frühe Fusion an. Hier wird concatenation zur frühen Fusion innerhalb einer gemeinsamen Repräsentation verwendet. Der gleiche Code wird angewendet. Am Ende wird eine einfache lineare Klassifikation durchgeführt, um zu bestimmen, ob ein Bild eine Katze enthält oder nicht.
from transformers import AutoModel, AutoProcessor, AutoTokenizer
from PIL import Image
import torch
import requests
import matplotlib.pyplot as plt
# 이미지와 텍스트를 위한 사전 학습된 모델 및 프로세서/토크나이저 로드
image_model_name = "google/vit-base-patch16-224-in21k" # ViT (Vision Transformer)
text_model_name = "bert-base-uncased" # BERT
image_processor = AutoProcessor.from_pretrained(image_model_name)
image_model = AutoModel.from_pretrained(image_model_name)
tokenizer = AutoTokenizer.from_pretrained(text_model_name)
text_model = AutoModel.from_pretrained(text_model_name)
# 예제 이미지 및 텍스트
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "Two cats sleeping on a couch."
# 이미지 출력
plt.imshow(image)
plt.axis('off') # 축 제거
plt.show()
# 이미지와 텍스트 전처리
image_inputs = image_processor(images=image, return_tensors="pt")
text_inputs = tokenizer(text, return_tensors="pt")
# 각 모달리티에 대한 특징 추출 (임베딩)
with torch.no_grad(): # 기울기 계산 비활성화 (추론 모드)
image_features = image_model(**image_inputs).last_hidden_state[:, 0, :] # [CLS] 토큰 임베딩
text_features = text_model(**text_inputs).last_hidden_state[:, 0, :] # [CLS] 토큰 임베딩
# Joint Representation 생성 (Concatenation)
joint_representation = torch.cat((image_features, text_features), dim=1)
print("Image Features Shape:", image_features.shape) # 이미지 특징 벡터 크기
print("Text Features Shape:", text_features.shape) # 텍스트 특징 벡터 크기
print("Joint Representation Shape:", joint_representation.shape) # 결합된 특징 벡터 크기 (image + text)
# Joint Representation을 활용한 추가 작업 (예: 분류)
num_labels = 2 # 예: "고양이 없음(0)" "고양이 있음(1)", 두 가지 클래스로 분류
classifier = torch.nn.Linear(joint_representation.size(1), num_labels) # 간단한 선형 분류기
outputs = classifier(joint_representation)
print("Classification Outputs:", outputs)Fast image processor class <class 'transformers.models.vit.image_processing_vit_fast.ViTImageProcessorFast'> is available for this model. Using slow image processor class. To use the fast image processor class set `use_fast=True`.
Image Features Shape: torch.Size([1, 768])
Text Features Shape: torch.Size([1, 768])
Joint Representation Shape: torch.Size([1, 1536])
Classification Outputs: tensor([[0.1817, 0.0355]], grad_fn=<AddmmBackward0>)In dem obigen Beispiel werden Bild und Text direkt mit den Ausgaben separater Modelle namens ViT und BERT kombiniert. Es wird keine zusätzliche Verarbeitung (z.B. Aufmerksamkeit, komplexe Transformationen) der beiden Vektoren durchgeführt, bevor die Bild- und Textmerkmale kombiniert werden. Daher entspricht dies einer frühen Fusion.
Die späte Fusion verarbeitet jede Modalität mit separaten Modellen und kombiniert die Ausgaben der Modelle in einem letzten Schritt (z.B. Vorhersageergebnisse). Der Vorteil dieses Ansatzes besteht darin, dass modalspezifische Modelle verwendet werden können. Zum Beispiel kann ein vorgefertigtes CNN für Bilder und eine vorgefertigte Transformer-Struktur für Texte verwendet werden, um die komplexen Merkmale jeder Modalität effektiv zu extrahieren. Ein Nachteil besteht jedoch darin, dass nur hochstufige (high-level) Interaktionen zwischen den Modalitäten berücksichtigt werden und ein Informationsaustausch in Zwischenschritten schwierig ist.
Die späte Fusion ähnelt Ensemble-Techniken, bei denen die Ausgaben verschiedener modalspezifischer Modelle kombiniert werden, um die Leistung zu verbessern. Dieses Forschungsfeld ist sehr aktiv.
Die hybride Fusion kombiniert Early Fusion und Late Fusion. Die Fusion wird in verschiedenen Schritten des Modells durchgeführt, um Informationen auf verschiedenen Ebenen zu nutzen. Der Vorteil dieses Ansatzes besteht darin, dass sowohl die Vorteile der Early Fusion als auch die der Late Fusion erzielt werden können. Das heißt, sowohl niedrigstufige (low-level) Interaktionen als auch hochstufige Interaktionen zwischen den Modalitäten berücksichtigt werden können. Ein Nachteil besteht jedoch darin, dass die Modellstruktur komplexer wird und viele Hyperparameter angepasst werden müssen.
Ein prominentes Beispiel für hybride Fusion ist die Cross-Modal Attention, bei der Merkmale einer Modalität als Abfrage (query) verwendet werden, um Aufmerksamkeit auf die Merkmale (key-value) der anderen Modalität anzuwenden. Dies ist eine typische Methode zur Durchführung von Fusion in Zwischenschritten.
In jüngsten Forschungen wird neben der Aufmerksamkeit auch Mechanismen wie gated mechanisms und bilinear pooling untersucht, um die Fusion in Zwischenschritten auf verschiedene Weise zu realisieren.
Seit 2023 haben moderne große multimodale Modelle (LMMs) wie Gemini und GPT-4V durch die Einführung von noch raffinierteren Modalitätsintegrationsstrategien ihre Leistung erheblich verbessert.
Das modalspezifische Integrationsverfahren optimiert den Modality-Fusionsansatz anhand der Anforderungen spezifischer Aufgaben. Bei der Bildunterschriftung (Image Captioning) wird der Fokus auf die unidirektionale Transformation von visuellen Informationen in Text gelegt, während bei visueller Frage-Antwort-Interaktion (VQA) bidirektionale Informationsaustausch verstärkt wird.
Diese sophistizierten Integrationsstrategien haben die Leistung multimodaler Modelle erheblich verbessert. Insbesondere ermöglichen sie nicht nur einfache Informationskombination, sondern regeln auch dynamisch die Rolle und Bedeutung jeder Modalität sowie optimieren die Fusionsmethode anhand der Eigenschaften der Aufgabe, was zu herausragenden Ergebnissen in komplexen Inferenzaufgaben führt. Diese Integrationsstrategien erfordern große Datensätze und Rechenressourcen, daher ist es schwierig, sie direkt durch eigene Implementierungen und Experimente zu erlernen. Stattdessen ist es ratsam, konzeptionelle Verständnis durch die Lektüre von Papers und technischen Dokumenten zu den einzelnen Modellen zu gewinnen.
In Abschnitt 10.3 haben wir verschiedene theoretische Methoden und Strategien zur Fusion von multimodalen Daten betrachtet. Auf dieser Grundlage werden wir nun spezifische Techniken untersuchen, wie tatsächliche multimodale Modelle die Informationen jeder Modalität effektiv darstellen und Beziehungen zwischen verschiedenen Modalitäten lernen. Die gesamte Implementierung befindet sich in chapter_10/multimodal_embeding.py.
Eine der Kernaufgaben im multimodalen Lernen besteht darin, verschiedene Modalitäten mit unterschiedlichen Eigenschaften in einen sinnvollen gemeinsamen Raum zu übersetzen. Bilder sind 2D-Arrays von Pixelwerten, Texte sind 1D-Sequenzen von Token und Audio ist eine Reihe von Amplitudenwerten über die Zeit; jede Modalität hat ihre eigene einzigartige Darstellungsweise. Um diese heterogenen Daten effektiv zu verarbeiten, sind Darstellungslern-Techniken erforderlich, die die wesentlichen Eigenschaften jeder Modalität beibehalten und gleichzeitig ihre semantischen Beziehungen erfassen können.
Früher Ansatz: Individuelle Encoder + Projektion
Frühe multimodale Modelle nutzten spezialisierte Encoder für jede Modalität (z.B. CNNs für Bilder, RNNs für Text), um Merkmalsvektoren zu extrahieren und diese dann durch lineare Transformation oder flache MLPs (Multi-Layer Perceptrons) in einen gemeinsamen Vektorraum zu projizieren (siehe Abschnitt 10.3.1: Gemeinsame Darstellung, Konkatenierung).
Neuere Ansätze: Semantische Ausrichtung
In jüngster Zeit dominiert die Methode, Merkmalsvektoren jeder Modalität so zu lernen, dass sie semantisch untereinander “ausgerichtet” sind. D.h., verwandte Bilder und Texte sollten im Einbettungsraum nah beieinander liegen, während unverwandte Bilder und Texte weiter voneinander entfernt sind.
Kontrastives Lernen: (siehe Abschnitt 10.3.2: Koordinierte Darstellung, Beispiel CLIP) Bild-Text-Paare werden als “positive” Beispiele betrachtet, zufällig gemischte Bild-Text-Paare als “negative” Beispiele. Das Lernen erfolgt so, dass die Ähnlichkeit zwischen positiven Beispielen erhöht und die Ähnlichkeit zwischen negativen Beispielen verringert wird.
Tripletten-Loss: Drei Elemente werden verwendet: ein Bild-Anker (anchor), ein positives Textbeispiel (die Caption des Ankerbildes) und ein negatives Textbeispiel (die Caption eines anderen Bildes). Das Lernen erfolgt so, dass der Abstand zwischen dem Ankerbild und dem positiven Text minimiert wird, während der Abstand zwischen dem Ankerbild und dem negativen Text maximiert wird.
Implementierungsbeispiel (Kontrastives Lernen)
class MultimodalEmbedding(nn.Module):
def __init__(self, embedding_dim=512):
super().__init__()
self.image_encoder = models.resnet18(pretrained=True)
self.image_encoder.fc = nn.Sequential(
nn.Linear(512, embedding_dim),
nn.LayerNorm(embedding_dim)
)
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.text_projection = nn.Sequential(
nn.Linear(768, embedding_dim), # BERT output dimension is 768
nn.LayerNorm(embedding_dim)
)
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
def encode_image(self, image):
return self.image_encoder(image)
def encode_text(self, input_ids, attention_mask):
text_features = self.text_encoder(input_ids, attention_mask)[0][:, 0, :] # [CLS] token, keep batch dim
return self.text_projection(text_features)MultimodalEmbedding Klasse:
image_encoder: Verwendet ResNet18, um Bilder in Merkmalsvektoren der Größe embedding_dim zu konvertieren.text_encoder: Verwendet ein BERT-Modell, um Text in Merkmalsvektoren zu konvertieren und durch die text_projection-Schicht auf die Größe embedding_dim anzugleichen.logit_scale: Ein lernbarer Temperaturparameter, wie bei CLIP verwendet.Semantische Ausrichtungsmechanismus
Die semantische Ausrichtung wird hauptsächlich in den folgenden zwei Teilen implementiert: der forward-Methode der Klasse MultimodalEmbedding und constrasive_loss().
def forward(self, image, input_ids, attention_mask):
image_features = self.encode_image(image)
text_features = self.encode_text(input_ids, attention_mask)
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
logit_scale = self.logit_scale.exp()
logits = logit_scale * image_features @ text_features.transpose(-1, -2)
# print("logits:", logits.shape)
return logits # Return a single valueforward Methode:
Verwenden Sie encode_image und encode_text, um die Bilder und Texte jeweils zu kodieren.
Merkmalsnormalisierung (Feature Normalization): Durch Anwendung der L2-Normalisierung (L2 normalization) werden die Längen der Vektoren image_features und text_features auf 1 gesetzt. Dies dient dazu, nur die Richtung der Vektoren zu berücksichtigen, um Ähnlichkeiten zu berechnen.
Temperaturkalibrierung (Temperature Scaling): Verwenden Sie logit_scale, um die Verteilung der Ähnlichkeitsbewertungen anzupassen. Wenden Sie die Exponentialfunktion auf logit_scale an, um den Skalierungsfaktor zu erhalten, und multiplizieren Sie diesen mit dem Matrizenprodukt der Bildmerkmalsmatrix und der transponierten Textmerkmalsmatrix. Das Matrizenprodukt berechnet die Skalarprodukte (inner products) zwischen jedem Vektor der Bildmerkmale und allen Vektoren der Textmerkmale, um Ähnlichkeitsbewertungen zu erzeugen.
logits: Berechnen Sie die Ähnlichkeit (Skalarprodukt) zwischen den Vektoren der Bildmerkmale und den Vektoren der Textmerkmale. Verwenden Sie text_features.transpose(-1, -2) anstelle von text_features.t(), um die Transposition durchzuführen. Dies vertauscht die letzten beiden Dimensionen der Textmerkmalsmatrix (Batch, Textmerkmaldimension) zu (Batch, Merkmalsdimension, Text), sodass sie mit der Bildmerkmalsmatrix in Form von (Batch, Bildmerkmaldimension) multipliziert werden kann.
def contrastive_loss(logits): # removed enhanced_similarity
labels = torch.arange(logits.size(0), device=logits.device) # Use logits.size(0)
# Image-to-text and text-to-image contrastive loss
img_txt_loss = nn.CrossEntropyLoss()(logits, labels)
txt_img_loss = nn.CrossEntropyLoss()(logits.T, labels)
# Average loss
return (img_txt_loss + txt_img_loss) / 2In der Funktion contrastive_loss werden die labels als Ganzzahlen von 0 bis (Batchgröße - 1) generiert, um der Größe der logits-Matrix anzupassen. Die diagonalen Elemente (i, i) in der logits-Matrix repräsentieren die Ähnlichkeit zwischen dem i-ten Bild und dem i-ten Text. Daher, da sie die Ähnlichkeit von Bildern und Texten darstellen, die einander entsprechen (positive Paare), werden die Labels so gesetzt, dass diese diagonalen Elemente die korrekten Antworten sind. Darüber hinaus berechnet img_txt_loss den Verlust der Ähnlichkeit von Bild zu Text (image-to-text loss) und txt_img_loss den Verlust der Ähnlichkeit von Text zu Bild (text-to-image loss). Durch das Durchschnittsbilden dieser beiden Verluste wird berücksichtigt, dass sowohl die bidirektionale (image-to-text, text-to-image) semantische Ausrichtung gewahrt bleibt.
Das Mechanismus der semantischen Ausrichtung bildet Merkmale verschiedener Modalitäten in einen semantisch konsistenten Raum ab. Zunächst werden alle Merkmalsvektoren durch L2-Normalisierung auf die Einheitssphäre projiziert, um Skalenunterschiede zwischen den Modalitäten zu eliminieren. Durch Einführung eines Temperatur-skalierenden Parameters wird die Verteilung der Ähnlichkeitswerte angepasst. Eine hohe Temperatur erzeugt eine glattere Verteilung, während eine niedrige Temperatur eine schärfere Verteilung erzeugt, um die Stabilität des Trainings zu erhöhen. Darüber hinaus wird durch kontrastives Lernen gelernt, dass zugehörige Bild-Text-Paare im Embedding-Raum näher und unzugehörige Paare weiter voneinander entfernt sind. Insbesondere werden die Abbildungen von Bild zu Text und von Text zu Bild gleichzeitig optimiert, um eine bidirektionale semantische Ausrichtung zu erzielen.
Ähnlich wie bei CLIPs kontrastivem Lernen werden zugehörige Inhalte näher und unzugehörige Inhalte weiter voneinander entfernt gelernt. Diese Strategie der semantischen Ausrichtung auf Basis des kontrastiven Lernens hat sich seit 2021 mit OpenAIs CLIP entwickelt, gefolgt von Googles PaLM-E, Anthropics Claude und DeepMinds Gemini. Während das ursprüngliche CLIP sich hauptsächlich auf einfaches kontrastives Lernen von Bild-Text-Paaren konzentrierte, erfassen neueste Modelle die gegenseitigen Beziehungen zwischen mehreren Modalitäten noch differenzierter. Insbesondere lernt Gemini die semantische Ausrichtung zwischen verschiedenen Modalitäten wie Bild, Text, Audio und Video gleichzeitig, wobei es die einzigartigen Eigenschaften jeder Modalität beibehält und einen integrierten semantischen Raum erstellt.
Beispiel-Ausführung
Für das Training wird der Datensatz flickr8k verwendet. Mit der Funktion train_multimodal_embedding kann das Modell EnhancedMultimodalEmbedding (oder EnhancedMultimodalEmbedding_no_p) auf dem Flickr8k-Datensatz trainiert werden. In der main-Funktion werden Modell, Datenlader und Optimizer konfiguriert, und durch den Aufruf der Funktion train_multimodal_embedding beginnt das Training.
# download flickr8k.
!mkdir data;cd data;wget "https://github.com/awsaf49/flickr-dataset/releases/download/v1.0/flickr8k.zip";unzip -q flickr8k.zip -d ./flickr8kmkdir: cannot create directory ‘data’: File exists
--2025-03-09 16:33:12-- https://github.com/awsaf49/flickr-dataset/releases/download/v1.0/flickr8k.zip
Resolving github.com (github.com)... 20.200.245.247
Connecting to github.com (github.com)|20.200.245.247|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://objects.githubusercontent.com/github-production-release-asset-2e65be/753516996/d7c62b13-1e50-40ea-8fae-f34a44b1695f?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=releaseassetproduction%2F20250309%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20250309T073156Z&X-Amz-Expires=300&X-Amz-Signature=ff62cf7df8ac3deba8bd6f4f775e164abf03c6d2d6d86d740e5407e52702c6a3&X-Amz-SignedHeaders=host&response-content-disposition=attachment%3B%20filename%3Dflickr8k.zip&response-content-type=application%2Foctet-stream [following]
--2025-03-09 16:33:12-- https://objects.githubusercontent.com/github-production-release-asset-2e65be/753516996/d7c62b13-1e50-40ea-8fae-f34a44b1695f?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=releaseassetproduction%2F20250309%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20250309T073156Z&X-Amz-Expires=300&X-Amz-Signature=ff62cf7df8ac3deba8bd6f4f775e164abf03c6d2d6d86d740e5407e52702c6a3&X-Amz-SignedHeaders=host&response-content-disposition=attachment%3B%20filename%3Dflickr8k.zip&response-content-type=application%2Foctet-stream
Resolving objects.githubusercontent.com (objects.githubusercontent.com)... 185.199.109.133, 185.199.111.133, 185.199.110.133, ...
Connecting to objects.githubusercontent.com (objects.githubusercontent.com)|185.199.109.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1112971163 (1.0G) [application/octet-stream]
Saving to: ‘flickr8k.zip’
flickr8k.zip 100%[===================>] 1.04G 56.8MB/s in 19s
2025-03-09 16:33:32 (56.9 MB/s) - ‘flickr8k.zip’ saved [1112971163/1112971163]
import torch
from torchvision import models, transforms
from torch.utils.data import Dataset, DataLoader
# Assuming dldna.chapter_10.multimodal_embedding is in the same directory or Python path.
# Adjust if necessary (e.g., from multimodal_embedding import ...).
from dldna.chapter_10.multimodal_embedding import Flickr8kDataset, MultimodalEmbedding, train_multimodal_embedding, generate_example
# Data transformation setup
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# Dataset and DataLoader setup
image_dir = './data/flickr8k/Images' # Replace with the actual path to your image directory
caption_file = './data/flickr8k/captions.txt' # Replace with the actual path to your caption file
dataset = Flickr8kDataset(image_dir, caption_file, transform=transform)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4)
# Model initialization
model = MultimodalEmbedding()
# Model training
train_multimodal_embedding(model, train_loader, val_loader, num_epochs=3)
# Model saving
torch.save(model.state_dict(), 'multimodal_embedding_model.pth')
# Example generation
model_path = 'multimodal_embedding_model.pth'
generate_example(model_path, image_dir, caption_file)Epoch 1/3: 15%|█▍ | 147/1012 [00:16<01:36, 8.96it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 1/3: 100%|██████████| 1012/1012 [01:53<00:00, 8.90it/s]Epoch 1/3 - Train Loss: 0.9618Epoch 1/3 - Validation Loss: 0.5212
Epoch 1: Saved best model with Validation Loss = 0.5212Epoch 2/3: 52%|█████▏ | 525/1012 [00:59<00:55, 8.84it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 2/3: 100%|██████████| 1012/1012 [01:54<00:00, 8.83it/s]Epoch 2/3 - Train Loss: 0.3393Epoch 2/3 - Validation Loss: 0.4240
Epoch 2: Saved best model with Validation Loss = 0.4240Epoch 3/3: 34%|███▍ | 347/1012 [00:39<01:15, 8.85it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 3/3: 100%|██████████| 1012/1012 [01:54<00:00, 8.83it/s]Epoch 3/3 - Train Loss: 0.2313Epoch 3/3 - Validation Loss: 0.3891
Epoch 3: Saved best model with Validation Loss = 0.3891
Image 0:
Top 3 Captions (Image -> Text):
- football players in red congratulate each other as crowds in red cheer behind. (prob: 0.9970)
- a man in black holds up an obama 08 sign. (prob: 0.0023)
- a large group of bicycles racing on the street (prob: 0.0004)
Caption: football players in red congratulate each other as crowds in red cheer behind.
Top 3 Images (Text -> Image):
- Image 0 (prob: 0.9983)
- Image 17 (prob: 0.0013)
- Image 2 (prob: 0.0001)
Kreuzmodaler Aufmerksamkeit wird verwendet, um Beziehungen zwischen verschiedenen Modalitäten effektiv zu modellieren. Dies erweitert die Selbst-Aufmerksamkeit des ViT, um Interaktionen zwischen heterogenen Daten wie Bildern und Text ermöglichen zu können.
Aufmerksamkeitsdesign zwischen den Modalitäten
Kreuzmodaler Aufmerksamkeit verfügt über eine asymmetrische Struktur, die die Eigenschaften jeder Modalität berücksichtigt.
class CrossModalAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.image_proj = nn.Linear(config.image_dim, config.hidden_dim)
self.text_proj = nn.Linear(config.text_dim, config.hidden_dim)
self.attention = nn.MultiheadAttention(config.hidden_dim, config.num_heads)
def forward(self, image_features, text_features):
image_proj = self.image_proj(image_features)
text_proj = self.text_proj(text_features)
attn_output, _ = self.attention(text_proj, image_proj, image_proj)
return attn_outputNach der Projektion von Bild- und Textmerkmalen in einen gemeinsamen latenten Raum lernen wir die Beziehung zwischen den beiden Modalitäten durch ein Multi-Head-Aufmerksamkeitsmechanismus. Dabei werden die Textmerkmale als Abfragen, die Bildmerkmale als Schlüssel und Werte verwendet, um sicherzustellen, dass der Text auf relevante Bereiche des Bildes achtet.
Asymmetrisches Aufmerksamkeitsmuster
Um die eindeutigen Eigenschaften jeder Modalität zu bewahren und dennoch eine effektive Informationsaustausch zu ermöglichen, verwenden wir ein asymmetrisches Aufmerksamkeitsmuster.
class HierarchicalCrossModalAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.local_image_attention = nn.MultiheadAttention(config.hidden_dim, config.num_heads)
self.local_text_attention = nn.MultiheadAttention(config.hidden_dim, config.num_heads)
self.image_to_text_attention = CrossModalAttention(config)
self.text_to_image_attention = CrossModalAttention(config)
self.output_layer = nn.Linear(config.hidden_dim * 2, config.hidden_dim)
def forward(self, image_features, text_features):
local_image = self.local_image_attention(image_features, image_features, image_features)[0]
local_text = self.local_text_attention(text_features, text_features, text_features)[0]
image_attended_text = self.image_to_text_attention(image_features, local_text)
text_attended_image = self.text_to_image_attention(text_features, local_image)
combined_features = torch.cat([image_attended_text, text_attended_image], dim=-1)
output = self.output_layer(combined_features)
return outputHier wird eine bidirektionale Aufmerksamkeit von Bildern zu Text und von Text zu Bildern getrennt durchgeführt. Dies ermöglicht es jeder Modalität, sich selektiv auf relevante Informationen der anderen Modalität zu konzentrieren.
Hierarchische Aufmerksamkeitsstruktur
Um komplexe multimodale Beziehungen zu erfassen, werden mehrere Schichten von Aufmerksamkeit hierarchisch organisiert. In den unteren Schichten werden lokale Merkmale innerhalb jeder Modalität verarbeitet und in den oberen Schichten werden die globalen Beziehungen zwischen den Modalitäten modelliert. Diese hierarchische Struktur spielt eine zentrale Rolle in Modellen wie GPT-4V und Gemini.
class EnhancedMultimodalEmbedding_no_p(MultimodalEmbedding):
def forward(self, image, input_ids, attention_mask):
image_features = self.encode_image(image)
text_features = self.encode_text(input_ids, attention_mask)
image_features = self.image_preserve(image_features)
text_features = self.text_preserve(text_features)
combined_features = self.cross_modal_attention(image_features, text_features)
combined_features = combined_features / combined_features.norm(dim=-1, keepdim=True)
logit_scale = self.logit_scale.exp()
logits = logit_scale * combined_features @ combined_features.t()
return logitsimport torch
from torchvision import models, transforms
from torch.utils.data import Dataset, DataLoader
from collections import namedtuple
from dldna.chapter_10.crossmodal_attention import Flickr8kDataset, CrossModalEmbedding, train_crossmodal_embedding, generate_example
# Configuration
config = namedtuple('Config', ['embedding_dim', 'image_dim', 'text_dim', 'hidden_dim', 'num_heads'])(
embedding_dim=512, # Output embedding dimension
image_dim=512, # ResNet18 image encoder output dimension
text_dim=512, # Text feature (768 from BERT -> 512 after projection)
hidden_dim=512, # Cross-modal attention internal hidden dimension
num_heads=8 # Number of multi-head attention heads
)
# Data transformation setup
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# Dataset and DataLoader setup
image_dir = './data/flickr8k/Images' # Change to the actual path
caption_file = './data/flickr8k/captions.txt' # Change to the actual path
dataset = Flickr8kDataset(image_dir, caption_file, transform=transform)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4, pin_memory=True)
# Model initialization
model = CrossModalEmbedding(config)
# Model training
train_crossmodal_embedding(model, train_loader, val_loader, num_epochs=3)
# Model saving
torch.save(model.state_dict(), 'crossmodal_embedding_model.pth')Epoch 1/3: 4%|▍ | 40/1012 [00:04<01:41, 9.53it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 1/3: 100%|██████████| 1012/1012 [01:47<00:00, 9.41it/s]Epoch 1/3 - Train Loss: 0.9663Epoch 1/3 - Validation Loss: 0.5378Epoch 2/3: 58%|█████▊ | 582/1012 [01:02<00:45, 9.36it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 2/3: 100%|██████████| 1012/1012 [01:48<00:00, 9.31it/s]Epoch 2/3 - Train Loss: 0.3381Epoch 2/3 - Validation Loss: 0.4452Epoch 3/3: 0%| | 4/1012 [00:00<02:27, 6.82it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 3/3: 100%|██████████| 1012/1012 [01:48<00:00, 9.35it/s]Epoch 3/3 - Train Loss: 0.2288Epoch 3/3 - Validation Loss: 0.3743# Example generation
model_path = 'crossmodal_embedding_model.pth'
generate_example(model_path, image_dir, caption_file)Image 0:
Top 3 Captions (Image -> Text):
- two people walk out onto the desert sand. (prob: 0.9862)
- a man takes a picture of him and his friend with his phone. (prob: 0.0092)
- the little boy wearing the blue shirt is putting dirt in his mouth. (prob: 0.0013)
Caption: two people walk out onto the desert sand.
Top 3 Images (Text -> Image):
- Image 0 (prob: 0.9898)
- Image 2 (prob: 0.0089)
- Image 4 (prob: 0.0005)
Perceiver ist eine multimodale Architektur, die 2021 von DeepMind vorgeschlagen wurde. Sie löst das Problem der quadratischen Komplexität traditioneller Transformer (die Berechnungsaufwand quadratisch mit der Länge des Eingabesequenzes ansteigt) und bietet eine Struktur, die verschiedene Modalitäten (Bilder, Text, Audio, Point Clouds usw.) effektiv verarbeitet. Perceiver ist besonders vorteilhaft, wenn die Größe der Eingangsdaten sehr groß ist (z.B. Hochauflösende Bilder, lange Texte). Hier wird eine allgemeine Beschreibung der Architektur gegeben und Beispiele werden weggelassen. Der Code dient als Beispiel zur Erläuterung.
Kernidee von Perceiver
Perceiver basiert auf den folgenden Ideen:
Perceiver verwendet einen festgelegten Größe des latenten Arrays, unabhängig von der Länge der Eingabesequenz. Dieses latente Array spielt die Rolle, die Informationen der Eingangsdaten zu komprimieren und darzustellen, ähnlich wie ein Flaschenhals große Mengen an Eingangsinformationen in eine kleinere Anzahl von latenten Vektoren zusammenfasst. Daher kann die Anzahl der latenten Vektoren (z.B. 256) festgelegt werden, unabhängig davon, wie groß die Eingangsdaten sind (z.B. 10,000 Tokens), was den Rechenaufwand und den Speicherverbrauch erheblich reduziert.
class Perceiver(nn.Module):
def __init__(self, ..., num_latents=256, latent_dim=512, ...):
super().__init__()
# Latent vector initialization (key!)
self.latents = nn.Parameter(torch.randn(num_latents, latent_dim))
# ...In dem folgenden Code stellt self.latents die latenten Vektoren dar. Es ist als nn.Parameter definiert und somit ein lernfähiger Parameter.
Der Perceiver verwendet keine modalspezifischen Verarbeitungsmethoden (z.B. CNN, RNN) für die Eingabemodalitäten (Bild, Text, Audio usw.). Stattdessen werden die Modalitäten durch einfache Vorverarbeitungsschritte (z.B. Bildpatchs, Texttokenisierung) in eine gemeinsame Form (sequence of vectors) transformiert. Anschließend wird unabhängig von der Modalitätstyp durch dieselbe transformer-basierte Architektur (Cross-Attention, Self-Attention) verarbeitet. Dies ermöglicht es, verschiedene Modalitäten flexibel zu verarbeiten und neue Modalitäten leicht hinzuzufügen.
Der Perceiver verwendet mehrere Schichten von Selbst-Aufmerksamkeit (self-attention), um die latenten Vektoren schrittweise zu aktualisieren. In jeder Schicht tauschen die latenten Vektoren Informationen aus und lernen komplexe Muster der Eingabedaten. Anfangs einfache Merkmale darstellende latente Vektoren entwickeln sich durch mehrere Schichten hinweg zu abstrakteren und hochgradig semantischen Darstellungen.
Funktionsweise des Perceivers (vereinfachtes Codebeispiel)
import torch
import torch.nn as nn
class Perceiver(nn.Module):
def __init__(self,
input_channels=3, # Input channels (e.g., RGB image)
input_axis=2, # Input dimension (image=2, video=3)
num_latents=256, # Number of latent vectors
latent_dim=512, # Latent vector dimension
num_heads=8, # Number of attention heads
depth=6): # Model depth (number of self-attention layers)
super().__init__()
# 1. Latent vector initialization (key!)
self.latents = nn.Parameter(torch.randn(num_latents, latent_dim))
# 2. Input projection (matches input dimension to latent dimension)
self.input_proj = nn.Linear(input_dim, latent_dim)
# 3. Cross-Attention (learns relationships between input and latent vectors)
# self.cross_attention = nn.MultiheadAttention(latent_dim, num_heads, batch_first=True)
# 4. Self-Attention (learns relationships between latent vectors) - repeated multiple times
self.self_attention_layers = nn.ModuleList([
nn.MultiheadAttention(latent_dim, num_heads, batch_first=True)
for _ in range(depth)
])
def forward(self, x): # x: Input data (image, text, ...)
batch_size = x.shape[0]
# 1. Input projection
x = self.input_proj(x)
# 2. Latent vector replication (for each item in the batch)
latents = self.latents.unsqueeze(0).expand(batch_size, -1, -1) # (B, num_latents, latent_dim)
# 3. (Optional) Cross-attention (between input and latent vectors)
# latents, _ = self.cross_attention(latents, x, x) # query, key, value
# 4. Self-attention (between latent vectors) - repeated multiple times
for layer in self.self_attention_layers:
latents, _ = layer(latents, latents, latents) # query, key, value
return latents # Return the processed latent vectorsVorteile und Nachteile des Perceivers
Der Perceiver zeichnet sich durch Effizienz aus, da seine Berechnungskomplexität fast konstant ist, unabhängig von der Eingabegröße. Er bietet Flexibilität, indem er verschiedene Modalitäten auf die gleiche Weise verarbeitet. Zudem bietet der Perceiver Skalierbarkeit, da neue Modalitäten leicht hinzugefügt werden können. Trotzdem hat der Perceiver aufgrund seiner Basis in den Transformers eine komplexe Struktur und kann sehr groß werden, wenn die Dimensionen der Latenten Vektoren und die Anzahl der Schichten zunehmen. Darüber hinaus kann er bei bestimmten Aufgaben wie Bildklassifizierung unterhalb von Modellen performen, die für diese Aufgabe spezialisiert sind, wie CNNs.
Perceiver IO
Das nachfolgende Forschungsprojekt Perceiver IO schlug einen Ansatz vor, bei dem nicht nur die Eingabe, sondern auch die Ausgabe über Latente Vektoren verarbeitet wird. Dies ermöglicht es, verschiedene Ausgabeformate (Klassifizierung, Regression, Sequenzgenerierung usw.) flexibel zu behandeln. Perceiver IO wird als ein allgemeineres und leistungsfähigeres Modell als der Perceiver bewertet.
Hier beginnen wir mit der grundlegenden Struktur des Cross-Attentions und vergleichen die Trainierbarkeit und Leistung, während wir allmählich Mechanismen hinzufügen. Auf diese Weise verstehen wir die Probleme, die bei multimodalem Lernen auftreten, und betrachten praktische Ansätze zur Lösung dieser Probleme.
Es ist sehr üblich und empfohlen, beim Design von Cross-Attention-Mechanismen, wie in diesem Abschnitt beschrieben, allmählich die Komplexität zu erhöhen. Diese Methode, auch als Ablationsstudie bekannt, ist effektiv zur Bestimmung der Wichtigkeit einzelner Konstruktionsmechanismen und zur Identifizierung von Schlusselmerkmalen, die zum Leistungserfolg des endgültigen Modells beitragen. Viele Papiere, in denen neue Architekturen vorgeschlagen werden, verwenden diese Herangehensweise. Darüber hinaus ist es aus praktischer Sicht sehr wichtig, nicht nur die endgültige Leistung zu diskutieren, sondern auch Stabilitätsprobleme während des Trainingsprozesses.
Vergleichende Trainierungsansätze
Die Experimente verwenden den bereits betrachteten flickr8k-Datensatz und trainieren die gegenseitige Ähnlichkeit zwischen Text und Bild mit zwei Eingaben. Beim Training ist eine Version der Cross-Attention festgelegt, wobei die Komplexität von Version zu Version zunimmt. In jeder Version wird ein Mechanismus der Cross-Attention hinzugefügt und das Training entsprechend durchgeführt, um Vergleiche vorzunehmen. Alle Trainings verwenden dieselben Hyperparameter, und die Anzahl der Trainings-Epochen ist auf 5 festgelegt.
Struktur des Beispiels
Das Beispiel hat folgende Struktur:
| Korean | German |
|---|---|
| Text | Text |
| Image | Bild |
chatper_10/mm
├── cat_resized.png
├── cross_attention
│ ├── v0.py
│ ├── v1.py
│ ├── v2.p
│ ├── v3.py
│ .... (weiterhin vorhanden)
├── train_multimodal.py
└── evaluate_models.pyDer Ordner cross_attention erhöht die Komplexität der Cross-Attention von v1 bis v11 schrittweise. train_mulimodal.py erstellt nach Abschluss eines Trainings dynamisch das nächste Modell, um das Training fortzusetzen. Während des Trainings werden Metriken wie Genauigkeit, Kontrastiver Verlust und Laufzeit gespeichert, um eine endgültige Vergleichstabelle zu erstellen. Es ist nicht ratsam, die Trainierbarkeit auf Grundlage von Verlustwerten und Genauigkeit zu beurteilen. Die einfachste Methode, um festzustellen, ob das Training korrekt durchgeführt wurde, besteht darin, es mit Daten zu bewerten, die bisher noch nicht vorhanden waren. Die Datei zum Evaluieren des Modells im Zero-Shot-Szenario ist evalute_models.py.
Das ausgewertete Bild lautet:

Die Bewertung wird durchgeführt, indem die Ähnlichkeit von fünf Texten mit dem obigen Bild gemessen wird.
test_captions = [
"A dog playing in the park",
"A cat sleeping on a couch",
"Children playing soccer",
"A sunset over the ocean",
"A person cooking in the kitchen"
]Wenn das Modell ordnungsgemäß trainiert wurde, sollte der zweite Eintrag “A cat sleeping on a couch” die höchste Ähnlichkeit aufweisen. Das obige Bild ist nicht Teil der Trainingsdaten und stellt einen typischen Zero-Shot-Test dar.
Dynamische Zuweisung der Cross-Attention
Die Version von cross_attention wird durch dynamische Zuweisung geändert.
from dldna.chapter_10.mm.cross_attention.v0 import CrossAttention as v0
from dldna.chapter_10.mm.cross_attention.v1 import CrossAttention as v1
# ... (import other versions) ...
from dldna.chapter_10.mm.cross_attention.v11 import CrossAttention as v11
def get_cross_attention(version, config=None):
if config is None:
config = {}
if version == 'v0':
return v0(**config)
elif version == 'v1':
return v1(**config)
# ... (other version conditions) ...
elif version == 'v11':
return v11(**config)
else:
raise ValueError(f"Invalid cross-attention version: {version}")
# ...
class ImageTextMatchingModel(nn.Module):
def __init__(self, image_encoder_dim=2048, text_encoder_dim=768, projection_dim=256):
super().__init__()
self.image_encoder = ImageEncoder(image_encoder_dim, projection_dim)
self.text_encoder = TextEncoder(text_encoder_dim, projection_dim)
# The CrossAttention module is dynamically assigned in main().
self.cross_attention = None # CrossAttention(projection_dim)
def forward(self, image, input_ids, attention_mask):
# ...
image_attended, text_attended = self.cross_attention(
image_features.unsqueeze(1),
text_features.unsqueeze(1)
)
# ...
# ...
def run_training(model_versions, ...):
# ...
for model_version in model_versions:
# ...
# Model initialization
model = ImageTextMatchingModel()
# Dynamically load the CrossAttention module
model.cross_attention = get_cross_attention(model_version, config=config)
# ...Dieser Abschnitt implementiert die Logik zum dynamischen Laden und Anwenden verschiedener Versionen des Cross-Attention-Moduls, was das Kernstück des Experiments ist. Die Funktion get_cross_attention nimmt eine Versionsnummer (v0, v1, …, v11) als Zeichenkette entgegen und gibt eine Instanz der entsprechenden CrossAttention-Klasse zurück. Im Inneren der Funktion run_training wird für jede Version in der Liste model_versions ein ImageTextMatchingModel initialisiert und die Funktion get_cross_attention aufgerufen, um das Cross-Attention-Modul der entsprechenden Version dem model.cross_attention zuzuweisen.
Diese dynamische Zuweisung erhöht die Wiederverwendbarkeit des Codes und vereinfacht die Experimentverwaltung. Wenn eine neue Version von Cross-Attention hinzugefügt wird, muss nur diese Version in der Funktion get_cross_attention integriert werden, so dass größere Änderungen am Trainingscode nicht erforderlich sind. Darüber hinaus kann leicht gesteuert werden, welche Versionen trainiert werden sollen, indem die Liste model_versions innerhalb der Funktion run_training angepasst wird.
Berechnung des Contrastive Loss und Trainingsschleife
def contrastive_loss(logits):
labels = torch.arange(len(logits), device=logits.device)
loss_i = nn.CrossEntropyLoss()(logits, labels)
loss_t = nn.CrossEntropyLoss()(logits.t(), labels)
return (loss_i + loss_t) / 2
def train(model, train_loader, val_loader, epochs=10, lr=1e-4, model_version='v0'):
# ...
for epoch in range(epochs):
model.train()
total_loss = 0
# ...
for batch in tqdm(train_loader, ...):
images, input_ids, attention_mask = [x.to(device) for x in batch]
optimizer.zero_grad()
logits = model(images, input_ids, attention_mask)
loss = contrastive_loss(logits)
loss.backward()
optimizer.step()
total_loss += loss.item()
# ... (validation 및 지표 계산) ...Dieser Abschnitt definiert die Berechnung des Contrastive Loss und den Trainingsloop, die für das Training des Modells verwendet werden. Die contrastive_loss Funktion nimmt Ähnlichkeitsbewertungen (Logits) von Bild-Text-Paaren als Eingabe und berechnet den Contrastive Loss. Dabei werden die korrekten Labels so generiert, dass die Elemente auf der Diagonale der Logits (d.h., die Bild-Text-Paare mit demselben Index) 1 (ähnlich) sind und alle anderen 0 (nicht ähnlich) sind (mit torch.arange). Es werden sowohl die Cross-Entropy-Loss basierend auf Bildern (loss_i) als auch der Cross-Entropy-Loss basierend auf Texten (loss_t) berechnet, wobei der Durchschnitt dieser beiden Werte als endgültiger Loss verwendet wird.
Trainingsmethode: Hinzufügen von Mechanismen
Wir werden die Funktionen schrittweise hinzufügen und testen, beginnend mit der einfachsten Aufmerksamkeitsstruktur. Diese hinzugefügten Funktionen nennen wir “Mechanismen”. Wir werden untersuchen, wie jeder hinzugefügte Mechanismus die Designierung multimodaler Aufmerksamkeit beeinflusst. Zuerst werfen wir einen Blick auf den Trainingscode und dann direkt auf die Trainingsresultate. Danach werden wir auch analysieren, welche Mechanismen bei der Kreuzmodalen Aufmerksamkeit entscheidend für den Erfolg oder Misserfolg des Trainings waren.
Der folgende Code ist der Trainingscode. Beim Training wird jedes Modell als model_final_{Version}.pth gespeichert. Mit diesen gespeicherten Modellen wird die Evaluation durchgeführt.
from dldna.chapter_10.mm.train_multimodal import run_training
# model_versions = ['v0', 'v1'] # List of model versions to train
model_versions = ['v0', 'v1', 'v2', 'v3', 'v4', 'v5', 'v6', 'v7', 'v8', 'v9', 'v10_1', 'v10_2', 'v10_3', 'v10_4', 'v10_5', 'v10_6', 'v11']
epochs = 5
lr = 1e-4
# Dataset
image_dir = './data/flickr8k/Images' # Change to the actual path
caption_file = './data/flickr8k/captions.txt' # Change to the actual path
results_df = run_training(model_versions, epochs=epochs, lr=lr, image_dir=image_dir, caption_file=caption_file) # Train multiple versions
# Print results
print("\nTraining Results:")
# Print results in Markdown table format
print(results_df.to_markdown(index=False))Das Modell führt die Bewertung durch.
from dldna.chapter_10.mm.evaluate_models import evaluate_all_models
# Test captions (fixed)
test_captions = [
"A dog playing in the park",
"A cat sleeping on a couch",
"Children playing soccer",
"A sunset over the ocean",
"A person cooking in the kitchen"
]
# Run model evaluation
image_path = './cat_resized.png'
model_dir = '.'
model_versions = ['v0', 'v1', 'v2', 'v3', 'v4', 'v5', 'v6', 'v7', 'v8', 'v9', 'v10_1', 'v10_2', 'v10_3', 'v10_4', 'v10_5', 'v10_6', 'v11']
results_df = evaluate_all_models(model_dir, image_path, test_captions, model_versions)
# Print results (Markdown table)
print(results_df.to_markdown(index=False))
# Print results (detailed)
for _, row in results_df.iterrows():
print(f"\nModel: {row['model_version']}")
print(f" Best Caption: {row['best_caption']}")
print(f" Trained Well: {row['trained_well']}")
print(f" Similarity Ratio: {row['similarity_ratio']}")
print(f" Similarity Gap: {row['similarity_gap']}")
print(" All Similarities:")
for caption, sim in zip(test_captions, row['all_similarities']):
print(f" - {caption:<30}: {sim}")| model_version | best_caption | all_similarities | similarity_ratio | similarity_gap | trained_well | similarity_ratio_rank |
|---|---|---|---|---|---|---|
| v0 | Eine Katze, die auf einem Sofa schläft | [‘5.322’, ‘15.477’, ‘-4.509’, ‘-6.609’, ‘2.107’] | 2.908 | 10.155 | True | 1 |
| v1 | Eine Katze, die auf einem Sofa schläft | [‘3.117’, ‘18.174’, ‘-6.475’, ‘-1.825’, ‘8.705’] | 2.088 | 9.469 | True | 3 |
| v2 | Eine Katze, die auf einem Sofa schläft | [‘3.085’, ‘12.541’, ‘-4.252’, ‘0.924’, ‘6.849’] | 1.831 | 5.692 | True | 5 |
| v3 | Kinder, die Fußball spielen | [‘34.882’, ‘34.882’, ‘34.882’, ‘34.882’, ‘34.882’] | 1 | 0 | False | 14 |
| v4 | Eine Katze, die auf einem Sofa schläft | [‘7.385’, ‘8.301’, ‘-1.038’, ‘-6.262’, ‘1.240’] | 1.124 | 0.915 | True | 12 |
| v5 | Kinder, die Fußball spielen | [‘27.357’, ‘27.357’, ‘27.357’, ‘27.357’, ‘27.357’] | 1 | 0 | False | 14 |
| v6 | Ein Hund, der im Park spielt | [‘33.967’, ‘33.302’, ‘31.580’, ‘32.710’, ‘31.384’] | 1.02 | 0.665 | False | 13 |
| v10_2 | Eine Katze, die auf einem Sofa schläft | [‘17.720’, ‘17.720’, ‘17.720’, ‘17.720’, ‘17.720’] | 1 | 0 | True | 14 |
| v10_3 | Eine Katze, die auf einem Sofa schläft | [‘0.516’, ‘1.479’, ‘-0.941’, ‘-0.106’, ‘0.694’] | 2.132 | 0.786 | True | 2 |
| v10_4 | Eine Katze, die auf einem Sofa schläft | [‘5.913’, ‘10.334’, ‘-5.989’, ‘-1.024’, ‘5.151’] | 1.748 | 4.421 | True | 6 |
| v10_5 | Eine Katze, die auf einem Sofa schläft | [‘6.601’, ‘9.990’, ‘-5.984’, ‘-2.988’, ‘-0.070’] | 1.513 | 3.389 | True | 8 |
| v10_6 | Ein Hund, der im Park spielt | [‘33.967’, ‘33.302’, ‘31.580’, ‘32.710’, ‘31.384’] | 1.02 | 0.665 | False | 13 |
| v11 | Eine Katze, die auf einem Sofa schläft | [‘11.315’, ‘15.491’, ‘-10.428’, ‘-0.004’, ‘10.014’] | 1.369 | 4.175 | True | 11 |
Auf Basis dieser Experimentsergebnisse können wir die Trainingsergebnisse für jede Version der Cross-Attention analysieren und die Gründe für den Trainingserfolg oder -misserfolg wie folgt zusammenfassen. - v1: Basic model using shared Q/K/V projections for both modalities. - v2: Separated Q/K/V projections for each modality to better capture modality-specific features. - v3: Added additional normalization layers after the attention mechanism to stabilize training. - v4: Introduced a residual connection between the input and output of the attention block to improve information flow. - v5: Enhanced the model with a gating mechanism to control the flow of information between modalities. The gating layer used sigmoid activation. - v6: Added separate context layers for each modality to preprocess features before attention. - v7: Introduced multi-head attention (MHA) to capture different aspects of the input features. - v8: Combined MHA with a layer normalization step before the attention mechanism to improve stability. - v9: Enhanced v8 by adding a gating mechanism and residual connections in the feed-forward network. - v10_1: Based on v9, added modality-specific Q/K/V projections to better capture unique features of each modality. - v10_2: Added cross-gating mechanism to control information flow between modalities. The gate layer lacked normalization and had a small initial scale. - v10_3: Added context layers for each modality to enrich feature representation before attention. - v10_4: Introduced multi-query attention (MQA) with shared K/V projections across heads to reduce parameter count while maintaining diverse query perspectives. - v10_5: Added hierarchical multi-head attention with level-wise feature processing and weighted fusion of outputs. - v10_6: Added contrastive learning-based similarity constraints to enhance feature representation. This distorted the original features, interfering with modality interaction. - v11: Combined MQA (from v10_4) and hierarchical fusion (from v10_5) to achieve parameter efficiency and multi-level feature integration. #### 10.4.4.3 Erklärung nach Aufmerksamkeitsstruktur
1. v0: Unabhängige bidirektionale Aufmerksamkeit - grundlegende Struktur
v0 implementiert die grundlegendste Form von Cross-Modal Attention. Es berechnet unabhängige Aufmerksamkeit für Bild und Text, wobei abgesehen von der skalierten Skalarprodukt-Aufmerksamkeit (Scaled Dot-Product Attention) keine anderen Normalisierungen oder Transformationen verwendet werden.
import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.scale = dim ** -0.5
def forward(self, image_features, text_features):
# Image -> Text attention
attn_i2t = torch.matmul(image_features, text_features.transpose(-2, -1)) * self.scale
attn_i2t = attn_i2t.softmax(dim=-1)
image_attended = torch.matmul(attn_i2t, text_features)
# Text -> Image attention
attn_t2i = torch.matmul(text_features, image_features.transpose(-2, -1)) * self.scale
attn_t2i = attn_t2i.softmax(dim=-1)
text_attended = torch.matmul(attn_t2i, image_features)
return image_attended, text_attendedv0 reagiert aufgrund des Fehlens eines separaten Normalisierungsprozesses empfindlich auf Änderungen der Skalierung der Eingabe-Features. Wenn die Skalierung der Eingabedaten während des Lernprozesses stark variiert, können die Aufmerksamkeitsgewichte instabil werden und das Training könnte nicht ordnungsgemäß erfolgen.
2. v2: geteilte Aufmerksamkeit + Layer Normalization
v2 ist eine Version, bei der Layer Normalization (LN) auf die Eingabe-Features angewendet wird, um die Skalierung der Features zu stabilisieren. v1 verwendete bereits die gleiche Aufmerksamkeitsmatrix (Gewichtsmatrix) und ihre Transponierte für die Berechnung von Bild→Text- und Text→Bild-Aufmerksamkeit, hatte aber den Nachteil, dass sie empfindlich auf Eingabeskaliert ist.
import torch
import torch.nn as nn
import torch.nn.functional as F
# Co-attention + added LN
class CrossAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.scale = dim ** -0.5
self.norm = nn.LayerNorm(dim) # Use a single LayerNorm
def forward(self, image_features, text_features):
# Input normalization
image_norm = self.norm(image_features)
text_norm = self.norm(text_features)
# Simple attention calculation
attn = torch.matmul(image_norm, text_norm.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# Bidirectional feature fusion (without residual connection)
image_out = torch.matmul(attn, text_norm)
text_out = torch.matmul(attn.transpose(-2, -1), image_norm)
return image_out, text_outimage_norm = self.norm(image_features) und text_norm = self.norm(text_features) wenden Layer Normalization auf die Eingabe-Features an. Layer Normalization führt die Normalisierung unabhängig für jedes Sample (jedes Bild oder Text innerhalb eines Minibatches) durch. Das heißt, es berechnet den Mittelwert und die Varianz des Merkmalsvektors jedes Samples, um diese auf 0 und 1 zu standardisieren. Dies stabilisiert das Lernen, indem es verhindert, dass die Aufmerksamkeitsgewichte divergieren, selbst wenn sich der Skalierungsbereich der Eingabe-Features stark ändert.
Trotzdem gibt es noch Einschränkungen. v2 löst das Problem der Eingabeskala durch Layer Normalization, verwendet aber dieselbe Aufmerksamkeitsmatrix für die Bild→Text- und Text→Bild-Aufmerksamkeit. Dies kann die asymmetrische Beziehung zwischen den beiden Modalitäten nicht ausreichend widerspiegeln. Die Generierung von Text aus Bildern und die Generierung von Bildern aus Text können unterschiedliche Komplexität aufweisen, was durch die gleiche Aufmerksamkeitsmechanik ineffektiv sein kann.
3. v3: v2 + Residual Connection - Fehlschlag
Seit der Einführung des ResNet-Modellarchitektur wurde die Residual Connection wie ein Glücksbringer in vielen Modellen verwendet, um das Gradient Vanishing Problem bei tieferen Netzwerken zu mildern und effektives Lernen tiefer Netzwerke zu ermöglichen. In diesem Experiment jedoch hat die Residual Connection zu einem Fehlschlag geführt, da sie die Leistung反而降低了。
请注意,最后一句话的翻译出现了语言混用的情况。正确的德语翻译应该是:
In diesem Experiment hat die Residual Connection jedoch zu einem Fehlschlag geführt, indem sie die Leistung反而降低了。改为: In diesem Experiment hat die Residual Connection jedoch zu einem Fehlschlag geführt, da sie die Leistung verschlechterte.
import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.scale = dim ** -0.5
self.norm = nn.LayerNorm(dim) # Use a single LayerNorm
def forward(self, image_features, text_features):
# Input normalization
image_norm = self.norm(image_features)
text_norm = self.norm(text_features)
# Simple attention calculation
attn = torch.matmul(image_norm, text_norm.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# Bidirectional feature fusion
image_attended = torch.matmul(attn, text_norm)
text_attended = torch.matmul(attn.transpose(-2, -1), image_norm)
# Add residual connection
image_out = image_features + image_attended
text_out = text_features + text_attended
return image_out, text_outIm Allgemeinen sind Residualverbindungen (Skip Connections) effektiv bei der Lösung des Problems, dass das Lernen mit tiefen Netzwerken schwieriger wird. In v3 führten sie jedoch aus folgenden Gründen zu einer Verschlechterung der Leistung.
Relativ flaches Netzwerk: Das v3-Modell hat eine vergleichsweise flache Netzstruktur, die nicht sehr tief ist. Residualverbindungen helfen bei tiefen Netzwerken stark dabei, das Problem des Gradientenverschwindens zu mildern. In flachen Netzwerken ist jedoch ihre Wirkung gering und sie können sogar den Informationsfluss stören.
Übermäßige Erhaltung ursprünglicher Merkmale: Der Kern der Cross-Modal Attention besteht darin, durch die Interaktion zwischen Bildern und Texten, zwei unterschiedlichen Modalitäten, neue Merkmale zu erzeugen. In v3 wurde jedoch das Ergebnis des Aufmerksamkeitsmechanismus durch das direkte Hinzufügen der ursprünglichen Merkmalsvektoren verwässert, was die Interaktion zwischen den beiden Modalitäten beeinträchtigte und zur Erzeugung neuer Merkmale führte. Das Modell konzentrierte sich also mehr auf die Erhaltung vorhandener Informationen als auf das Lernen neuer.
Die Experimente mit v3 liefern eine wichtige Lehre: Residualverbindungen sind keine universelle Lösung, um die Leistung zu verbessern. Sie sollten sorgfältig eingesetzt werden, unter Berücksichtigung der Tiefe des Netzwerks, des Anwendungsorts und der Eigenschaften des Problems. v3 ist ein typisches Beispiel für eine Verschlechterung der Leistung durch die unangemessene Verwendung von Residualverbindungen.
4. v8: Unabhängige Multi-Head Attention
In v8 wurden wichtige Änderungen eingeführt, um die Probleme der vorherigen Version (v7) zu beheben und die Leistung der Cross-Modal Attention zu verbessern. Insbesondere wurde die Bild→Text-Aufmerksamkeit und die Text→Bild-Aufmerksamkeit in unabhängige Multi-Head Attention getrennt. Darüber hinaus wurde Layer Normalization sowohl auf die Eingänge als auch auf die Ausgänge der Aufmerksamkeitsoperationen angewendet, um die Stabilität des Trainings weiter zu steigern.
import torch
import torch.nn as nn
import torch.nn.functional as F
# v8 - Independent multi-head
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
self.norm = nn.LayerNorm(dim)
# Projections for multi-head attention
self.to_q = nn.Linear(dim, dim)
self.to_k = nn.Linear(dim, dim)
self.to_v = nn.Linear(dim, dim)
# Output projection
self.to_out = nn.Linear(dim, dim)
# Add output normalization
self.out_norm = nn.LayerNorm(dim)
def forward(self, image_features, text_features):
B, N_i, _ = image_features.shape
_, N_t, _ = text_features.shape
H = self.num_heads
# Input normalization
image_norm = self.norm(image_features)
text_norm = self.norm(text_features)
def split_heads(x):
return x.reshape(B, -1, H, self.head_dim).transpose(1, 2)
# Image -> Text direction attention
q_img = split_heads(self.to_q(image_norm))
k_txt = split_heads(self.to_k(text_norm))
v_txt = split_heads(self.to_v(text_norm))
attn_i2t = torch.matmul(q_img, k_txt.transpose(-2, -1)) * self.scale
attn_i2t = attn_i2t.softmax(dim=-1)
image_attended = torch.matmul(attn_i2t, v_txt)
# Text -> Image direction attention
q_txt = split_heads(self.to_q(text_norm))
k_img = split_heads(self.to_k(image_norm))
v_img = split_heads(self.to_v(image_norm))
attn_t2i = torch.matmul(q_txt, k_img.transpose(-2, -1)) * self.scale
attn_t2i = attn_t2i.softmax(dim=-1)
text_attended = torch.matmul(attn_t2i, v_img)
# Combine heads and output projection
image_attended = image_attended.transpose(1, 2).reshape(B, N_i, -1)
text_attended = text_attended.transpose(1, 2).reshape(B, N_t, -1)
image_out = self.out_norm(self.to_out(image_attended))
text_out = self.out_norm(self.to_out(text_attended))
return image_out, text_outv7 hat zwar die Multi-Head-Aufmerksamkeit eingeführt, aber es wurden weiterhin dieselben Q, K, V-Transformationen für die Aufmerksamkeit von Bild zu Text und von Text zu Bild verwendet. Das bedeutet, da alle Köpfe die gleichen Q, K, V-Matrizen teilten, waren sie eingeschränkt in ihrer Fähigkeit, verschiedene Merkmale zu lernen, was zur Begrenzung der Ausdrucksstärke des Modells beitrug. v8 löste dieses Problem, indem es unabhängige Q, K, V-Transformationen für jede Richtung (Bild zu Text, Text zu Bild) und jeden Kopf anwendete, sodass das Modell viel flexiblere und reichhaltigere Merkmalsrepräsentationen lernen konnte.
5. v9: v8 + Pre-LN + FFN (gegatterter FFN + Dropout)
v9 baut auf der Struktur von v8 auf und fügt drei wichtige Mechanismen hinzu, um die Trainingsstabilität und Leistung weiter zu verbessern: die Pre-Layer Normalization, den gegatterten Feed-Forward Network (FFN) und den Dropout.
import torch
import torch.nn as nn
import torch.nn.functional as F
# v9 - Dropout before gated FFN, pass through norm at the end -> trainable
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8, dropout=0.1, ff_dim=None):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
ff_dim = ff_dim or dim * 4
# Normalization layers for Pre-LN
self.attn_norm = nn.LayerNorm(dim)
self.ff_norm = nn.LayerNorm(dim)
# Projections for multi-head attention
self.to_q = nn.Linear(dim, dim)
self.to_k = nn.Linear(dim, dim)
self.to_v = nn.Linear(dim, dim)
# Output projection
self.to_out = nn.Linear(dim, dim)
# Dropout
self.dropout = nn.Dropout(dropout)
# Gated feedforward network
self.ff_gate = nn.Sequential(
nn.Linear(dim, ff_dim),
nn.GELU(),
nn.Dropout(dropout)
)
self.ff_value = nn.Sequential(
nn.Linear(dim, ff_dim),
nn.GELU(),
nn.Dropout(dropout)
)
self.ff_out = nn.Linear(ff_dim, dim)
def forward(self, image_features, text_features):
B, N_i, _ = image_features.shape
_, N_t, _ = text_features.shape
H = self.num_heads
def split_heads(x):
return x.reshape(B, -1, H, self.head_dim).transpose(1, 2)
# Pre-LN: Normalize before attention
image_norm = self.attn_norm(image_features)
text_norm = self.attn_norm(text_features)
# Image -> Text direction attention
q_img = split_heads(self.to_q(image_norm))
k_txt = split_heads(self.to_k(text_norm))
v_txt = split_heads(self.to_v(text_norm))
attn_i2t = torch.matmul(q_img, k_txt.transpose(-2, -1)) * self.scale
attn_i2t = attn_i2t.softmax(dim=-1)
attn_i2t = self.dropout(attn_i2t) # Apply dropout to attention weights
image_attended = torch.matmul(attn_i2t, v_txt)
# Text -> Image direction attention
q_txt = split_heads(self.to_q(text_norm))
k_img = split_heads(self.to_k(image_norm))
v_img = split_heads(self.to_v(image_norm))
attn_t2i = torch.matmul(q_txt, k_img.transpose(-2, -1)) * self.scale
attn_t2i = attn_t2i.softmax(dim=-1)
attn_t2i = self.dropout(attn_t2i) # Apply dropout to attention weights
text_attended = torch.matmul(attn_t2i, v_img)
# Combine heads and output projection
image_attended = image_attended.transpose(1, 2).reshape(B, N_i, -1)
text_attended = text_attended.transpose(1, 2).reshape(B, N_t, -1)
# Output projection and dropout
image_attended = self.dropout(self.to_out(image_attended))
text_attended = self.dropout(self.to_out(text_attended))
# Residual connection - connecting the original image features makes training impossible.
# image_attended = image_attended + image_features
# text_attended = text_attended + text_features
# Pre-LN: Normalize before FFN
image_ff = self.ff_norm(image_attended)
text_ff = self.ff_norm(text_attended)
# Gated feedforward processing
def apply_ff(x):
gate = self.ff_gate(x)
value = self.ff_value(x)
return self.dropout(self.ff_out(gate * value))
# FFN output and residual connection - this type of residual connection is possible.
image_out = apply_ff(image_ff) + image_attended
text_out = apply_ff(text_ff) + text_attended
return image_out, text_outPre-Layer Normalization: In v8 wurde Layer Normalization nach den Aufmerksamkeitsoperationen angewendet (Post-LN), während in v9 die Normalisierung davor durchgeführt wird (Pre-LN). self.image_norm_q, self.image_norm_k, …, self.text_norm_v fallen hierunter. Pre-LN bietet höhere Trainierstabilität als Post-LN und erfordert keine separate Warmup-Phase, wodurch es in neueren Transformer-basierten Modellen häufiger eingesetzt wird.
Gatter Feed-Forward Network (FFN): In v8 wurde nach den Aufmerksamkeitsoperationen ein FFN hinzugefügt, um die Nichtlinearität zu verstärken und die Ausdrucksstärke des Modells zu erhöhen.
self.image_ffn und self.text_ffn definieren das FFN. Es besteht aus zwei linearen Layern (Linear Layer) mit GELU (Gaussian Error Linear Unit) Aktivierungsfunktion dazwischen sowie Dropout.self.image_ffn_norm, self.text_ffn_norm) angewendet. Im Gegensatz zu v3 erfolgt die Residualverbindung nach der FFN-Verarbeitung, um die Kombination von Informationen nach nichtlinearer Verarbeitung zu fördern, was den Informationsfluss verbessert und zur Leistungssteigerung beiträgt.Dropout: self.dropout definiert den Dropout, der auf die Aufmerksamkeitsgewichte und innerhalb des FFNs angewendet wird. Dropout ist eine effektive Regularisierungstechnik, bei der Neuronen während des Trainings zufällig deaktiviert werden, um das Overfitting zu verhindern.
Effekte der hinzugefügten Mechanismen
Durch diese Kombination von Techniken hat v9 die Leistung der Cross-Modal Attention erheblich gesteigert und eine Grundlage für nachfolgende Versionen gelegt.
v0, v1 (Grundstruktur): v0 und v1, die nur einfache Aufmerksamkeit ohne Normierung verwenden, wurden erfolgreich trainiert. Allerdings zeigte v1, obwohl es trainiert wurde, in Training- und Validierungsdatensätzen eine höhere Ähnlichkeit bei “Katze”-bezogenen Captions. Dies unterstreicht die Bedeutung der Normierung.
v2 (LayerNorm): v2, auf das LayerNorm auf den Eingaben angewendet wurde, wurde erfolgreich trainiert. Dies zeigt die Wichtigkeit, die Skalierung der Eingangseigenschaften zu stabilisieren.
v3 (Residualverbindungen): v3, bei dem Residualverbindungen zu v2 hinzugefügt wurden, scheiterte beim Training. Dies zeigt, dass Residualverbindungen in multimodalem Lernen nicht immer hilfreich sind. Residualverbindungen können die ursprünglichen Eigenschaften übermäßig beibehalten und so das Lernen der Interaktion zwischen den beiden Modalitäten behindern.
v4 (Projektion): v4, bei dem unabhängige lineare Transformationen (Projektion) zu jeder Modalität hinzugefügt wurden, wurde erfolgreich trainiert. Dies deutet darauf hin, dass es wichtig ist, die Merkmalsräume jeder Modalität angemessen zu transformieren.
v7 (geteilte Multiköpfe): v7, bei dem geteilte Aufmerksamkeitsmatrizen zu Multiköpfen erweitert wurden, scheiterte beim Training. Dies wird darauf zurückgeführt, dass jeder Kopf die Eigenschaften der verschiedenen Modalitäten nicht angemessen widerspiegeln konnte.
v8 (unabhängige Multiköpfe): v8, bei dem unabhängige Multikopfaufmerksamkeit für jede Richtung (Bild→Text, Text→Bild) verwendet und getrennte LayerNorms auf Eingang und Ausgang angewendet wurden, wurde erfolgreich trainiert. Dies zeigt die Bedeutung des Erhalts der Eigenschaften jeder Modalität und der Bereitstellung zusätzlicher Kontextinformationen für eine bessere Leistung.
v10_3 (geteilte Multiköpfe): v10_3, bei dem geteilte Multikopfaufmerksamkeit angewendet wurde, scheiterte beim Training. Dies könnte darauf zurückzuführen sein, dass die geteilten Köpfe nicht ausreichend divergierende Informationen bereitstellten.
v10_4 (Multifrage-Aufmerksamkeit): v10_4, bei dem Multifrage-Aufmerksamkeit angewendet wurde, wobei die Abfragen (Q) unabhängig beibehalten und die Schlüssel (K) und Werte (V) geteilt wurden, wurde erfolgreich trainiert. Dies zeigt, dass eine Reduzierung der Parameterzahl effizientes Informationsaustausch ermöglicht und die Verallgemeinerungsleistung verbessert.
v10_5 (hierarchische Multiköpfe): v10_5, bei dem eine dreistufige hierarchische Struktur eingeführt wurde und unabhängige Multikopfaufmerksamkeit auf jeder Ebene angewendet wurde, die dann durch Gewichtung fusioniert wurden, wurde erfolgreich trainiert. Dies zeigt, dass das schrittweise Integrieren von Merkmalen und das effektive Nutzen der Informationen auf jeder Ebene die Leistung erhöht.
v10_6 (kontrastives Lernen mit Multiköpfen): v10_6, bei dem separate Projektionsschichten für kontrastives Lernen hinzugefügt wurden und Ähnlichkeitsinformationen direkt zu den ursprünglichen Merkmalen addiert wurden, scheiterte beim Training. Dies könnte darauf zurückzuführen sein, dass die Ähnlichkeitsinformationen die ursprünglichen Merkmale verfälschten und das Lernen behinderten.
v11 (Multifrage + hierarchische Fusion): v11, das die Vorteile von Multifrage-Aufmerksamkeit (v10_4) und hierarchischer Multikopfaufmerksamkeit (v10_5) kombiniert, wurde erfolgreich trainiert. Dies bedeutet, dass sowohl Parameter-effizienz als auch schrittweise Merkmalsintegration genutzt wurden, um ein stabiles Training zu erreichen.
Schlussfolgerung
Durch diesen Abbaueffekt können wir folgende Schlussfolgerungen ziehen. 1. Die Bedeutung der Normalisierung: Die Anwendung von LayerNorm auf die Eingabe-Features ist für die Trainingsstabilität sehr wichtig (v2). 2. Die Janusgesichtigkeit des Residualverbindungen: Residualverbindungen sind ein nützliches Mechanismus, können jedoch in den frühen Phasen multimodalen Lernens eher schädlich sein (v3). Das übermäßige Beibehalten der ursprünglichen Features kann das Lernen der Interaktion zwischen beiden Modalitäten behindern. 3. Unabhängige Featuretransformation: Die Anwendung unabhängiger linearer Transformationen (Projektion) auf jede Modality kann die Leistung verbessern (v4). 4. Multi-Head-Aufmerksamkeit: Bei der Verwendung von Multi-Head-Aufmerksamkeit sollten die einzelnen Köpfe so konfiguriert sein, dass sie unterschiedliche Modalitäten unabhängig voneinander widerspiegeln (v7, v8). 5. Angemessene Komplexität: Die Überhöhung der Modellkomplexität kann das Training instabil machen (v10_1, v10_2, v10_6). 6. Effiziente Mechanismen: Multi-Query-Aufmerksamkeit (v10_4) und hierarchische Fusion (v10_5) bieten jeweils Vorteile in Bezug auf parameter-effizientes Lernen und schrittweise Merkmalsintegration. 7. Die Bedeutung der optimalen Kombination: Wie bei v11 zu sehen ist, kann die geeignete Kombination effektiver Mechanismen ein stabileres und leistungsfähigeres multimodales Lernmodell ermöglichen.
Diese Entfernungsversuche sind sehr nützlich für das Verständnis der Rolle und Bedeutung jeder Komponente im multimodalischen Lernen. Sie bieten wichtige Richtlinien für den Design von neuen Modellen. Durch die systematische Analyse der Leistungsänderungen aufgrund der Anwesenheit oder Abwesenheit bestimmter Mechanismen kann ermittelt werden, welche Elemente effektiv für die multimodale Fusion sind und welche Kombinationen zu optimalen Ergebnissen führen.
Mit einem stärker systematischen Versuchsaufbau und einem Framework für Projekte können auch Experimente mit großen Modellen und verschiedenen Mechanismen glatt durchgeführt werden. Es wird erhofft, dass dies der Forschung zugutekommt.
In diesem Abschnitt werfen wir einen Blick auf den Vision Transformer (Vision Transformer, ViT), der eine Revolution im Bereich der Bildverarbeitung gebracht hat, sowie auf Erweiterungen des ViT wie ViT-22B und MAE.
Im Jahr 2020 stellte das Google Research Team in ihrem Paper “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” den ViT der Welt vor. Der ViT war ein Fanfarenstoß, der anzeigte, dass das Zeitalter der konvolutionellen Neuronalen Netze (Convolutional Neural Network, CNN), die lange Zeit das Bildverarbeitungsgebiet beherrschten, zu Ende ging und eine neue Ära mit Transformer-basierten Modellen begann.
Das Kernkonzept des ViT ist einfach. Ein Bild wird in mehrere kleine Teile (Patches) aufgeteilt, und jeder Patch wird wie ein Wort (Token) in einem Textsatz behandelt. Auf diese Weise wird das Bild in eine Sequenz von Patches umgewandelt, die vom Transformer als Eingabe verarbeitet wird.
Im Vergleich zu CNNs hat der ViT folgende wichtige Unterschiede:
Lokalität (Locality) vs. Globalität (Globality): CNNs legen den Fokus darauf, lokale Merkmale eines Bildes durch die Verwendung von Faltungsfiltern (Convolution Filters) zu extrahieren. Im Gegensatz dazu kann der ViT durch das Aufmerksamkeitsmechanismus (Attention Mechanism) die Beziehungen jedes Patches zu allen anderen Patches im gesamten Bild direkt berücksichtigen. Dies bedeutet, dass er besser in der Lage ist, den Kontext des gesamten Bildes zu erfassen.
Hierarchische Struktur (Hierarchical Structure) vs. Flache Struktur (Flat Structure): CNNs haben eine hierarchische Struktur, die durch mehrere Ebenen von Faltungen (Convolutions) und Pooling-Operationen geprägt ist und Merkmale schrittweise abstrahiert. Dagegen werden bei ViT alle Patches nach der Aufteilung des Bildes in gleiche Vektordimensionen transformiert und auf einer Skala verarbeitet. Diese flache Struktur erleichtert die Implementierung und Optimierung des Modells.
Datenabhängigkeit: CNNs neigen dazu, auch bei relativ geringen Datenmengen gut zu funktionieren. ViT hingegen erfordert aufgrund der Eigenschaften von Transformer-basierten Modellen eine ausreichende Menge an Daten, um seine volle Leistung zu entfalten. Ein vorab mit einem großen Datensatz trainierter ViT zeigt in verschiedenen Visionstasks wie Bildklassifizierung und Objekterkennung bessere Ergebnisse als CNNs.
Die Einführung des ViTs hat die Forschungsrichtungen im Bereich der Bildverarbeitung grundlegend verändert. Seit dem Auftreten des ViT sind zahlreiche nachfolgende Studien erschienen, die auf Ideen wie Image Patch Embedding, Aufmerksamkeitsmechanismus und groß angelegtes Vortraining basieren.
Das Bild-Patch-Embedding ist der erste Schritt des ViT und beinhaltet den Prozess, ein zweidimensionales Bild in eine eindimensionale Sequenzform zu transformieren. In PyTorch übernimmt die Klasse torchvision.models.vision_transformer.PatchEmbed diese Aufgabe.
import torch
import torch.nn as nn
import torch.nn.functional as F
class PatchEmbed(nn.Module):
"""
Transforms a 2D image into a sequence of patch embeddings.
"""
def __init__(
self,
img_size: int = 224,
patch_size: int = 16,
in_chans: int = 3,
embed_dim: int = 768,
) -> None:
"""
Args:
img_size: The size of the input image (assuming a square image)
patch_size: The patch size (assuming square patches)
in_chans: The number of input image channels (e.g., 3 for RGB images)
embed_dim: The dimension of the patch embedding vector
"""
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) * (img_size // patch_size)
self.projection = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Transforms the input image into a sequence of patch embeddings.
Args:
x: Input image (shape: [batch_size, in_chans, img_size, img_size])
Returns:
Sequence of patch embeddings (shape: [batch_size, num_patches, embed_dim])
"""
x = self.projection(x) # [batch_size, embed_dim, num_patches_h, num_patches_w]
x = x.flatten(2) # [batch_size, embed_dim, num_patches]
x = x.transpose(1, 2) # [batch_size, num_patches, embed_dim]
return xDer wichtigste Teil der __init__-Methode der Klasse PatchEmbed ist self.projection = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size). Dieser eine Zeile Code führt sowohl die Bildpatcherstellung als auch das Embedding durch.
nn.Conv2d: Eine PyTorch-Schicht, die 2D-Faltungsaufgaben ausführt.in_chans: Die Anzahl der Kanäle des Eingangsbildes (3 für RGB-Bilder).embed_dim: Die Dimension des Ausgabe-Embedding-Vektors (768 im Fall des ViT-Base-Modells).kernel_size=patch_size: Die Größe des Faltungsfilters (Kernels) wird auf die Patchgröße eingestellt.stride=patch_size: Das Abstandsintervall, mit dem der Filter über das Bild gleitet, wird ebenfalls auf die Patchgröße gesetzt.Indem kernel_size und stride auf patch_size gesetzt werden, führt der Faltungsfilter die Aufgabe aus, das Bild in nicht überlappende, schachbrettartige Patches der festgelegten Größe zu teilen. Jeder Faltungsfilter komprimiert die Information eines einzelnen Patches und erzeugt einen Embedding-Vektor.
In der forward-Methode der Klasse PatchEmbed wird tatsächlich das Bildpatch-Embedding durchgeführt, indem self.projection(x) angewendet wird.
self.projection(x): Die Faltungsaufgabe (Conv2d) wird auf den Eingangsbild-Tensor x ([batch_size, in_chans, img_size, img_size]) angewendet. Das Ergebnis ist ein Tensor der Form [batch_size, embed_dim, num_patches_h, num_patches_w] (wobei num_patches_h und num_patches_w die Höhe und Breite des Bildes durch die Patchgröße geteilt sind).
x.flatten(2): Der Output von Conv2d wird in eine Form [batch_size, embed_dim, num_patches] flachgedrückt (flattened). num_patches ist die Gesamtzahl der Patches (num_patches_h * num_patches_w).
x.transpose(1, 2): Die Dimensionen des Tensors werden in eine Form [batch_size, num_patches, embed_dim] umgewandelt. Dies ist die Eingabeform für den Transformer-Encoder, bei der jeder Patch-Embedding-Vektor als Element einer Sequenz behandelt wird.
Letztendlich erstellt die Klasse PatchEmbed aus einem Bild Patches und transformiert jeden Patch in einen Vektor der Dimension embed_dim. Dies führt zu einer Sequenzform, die als Eingabe für den Transformer-Encoder verwendet werden kann.
ViT teilt ein Bild in Patches auf und behandelt jeden Patch ähnlich wie ein Wort in einem Text, um es dem Transformer zuzuführen. Allerdings erkennt der Transformer die Reihenfolgeinformationen der Eingabesequenz nicht selbstständig. Deshalb muss dem Modell mitgeteilt werden, an welcher Position sich jeder Patch im Bild befindet. Diese Aufgabe wird durch Positionscodierung (Positional Encoding) erfüllt.
In der VisionTransformer-Klasse von PyTorch werden trainierbare (learnable) Positions-Embeddings verwendet. Das bedeutet, dass für die Position jedes Patches ein eindeutiger Embedding-Vektor während des Trainingsprozesses zusammen optimiert wird.
class VisionTransformer(nn.Module):
def __init__(self, ..., num_patches, embed_dim, ...):
super().__init__()
# ...
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) # Class token
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim)) # Positional embedding
self.pos_drop = nn.Dropout(p=drop_rate)
# ...
def _pos_embed(self, x):
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1) # Prepend class token
x = x + self.pos_embed # Add positional embedding
return self.pos_drop(x)
def forward(self, x):
x = self.patch_embed(x) # Patch embedding
x = self._pos_embed(x) # Add positional embedding
# ... (Transformer Encoder etc.) ...Code Erläuterung
self.pos_embed (trainierbare Parameter): Wird als nn.Parameter definiert und wird während des Trainings aktualisiert. Es hat die Größe (1, num_patches + 1, embed_dim).
num_patches + 1: Die Addition von 1 zur Anzahl der Patches dient dazu, Platz für einen Klassentoken (class token) zu schaffen, der eine besondere Rolle spielt.embed_dim: Es hat die gleiche Dimension wie die Patch-Embeddings.embed_dim zugewiesen._pos_embed Methode:
self.cls_token wird am Anfang der Eingabe x (Patch-Embedding-Sequenz) hinzugefügt. Der cls_token wird so oft repliziert (expand), dass er für alle Bilder in der Batch-Größe angewendet werden kann.self.pos_embed hinzugefügt. Gemäß den Broadcasting-Regeln von PyTorch wird jeder Positions-Embedding-Vektor in self.pos_embed automatisch zu allen Patch-Embedding-Vektoren an der gleichen Position hinzugefügt.forward Methode: In der forward Methode werden die Bilder durch self.patch_embed(x) in Patch-Embeddings transformiert und anschließend wird self._pos_embed(x) aufgerufen, um die Positions-Embeddings hinzuzufügen.Zusammenfassung
ViT verwendet für jeden Patch (und den Klassentoken) trainierbare Positions-Embeddings, die zu den Patch-Embeddings addiert werden, um Positionsinformationen dem Modell zuzuführen. Da die Positions-Embeddings während des Training des Modells zusammen mit anderen Gewichten optimiert werden, können sie die Positionsinformationen in der für die Daten am besten geeigneten Form darstellen.
ViT (Vision Transformer) ist ein Modell, das Bilder wie Text verarbeitet, um Visionstasks wie Klassifizierung durchzuführen. In PyTorch kann das ViT-Modell über die Klasse torchvision.models.VisionTransformer verwendet werden.
class VisionTransformer(nn.Module):
def __init__(self, ..., embed_dim, depth, num_heads, ...):
super().__init__()
self.patch_embed = PatchEmbed(...) # Image patch embedding
self.cls_token = nn.Parameter(...) # Class token
self.pos_embed = nn.Parameter(...) # Positional embedding
self.pos_drop = nn.Dropout(...)
self.blocks = nn.Sequential(*[
TransformerEncoderLayer(...) for _ in range(depth) # Transformer Encoder blocks
])
self.norm = nn.LayerNorm(embed_dim) # Layer Normalization
self.head = nn.Linear(embed_dim, num_classes) # Classification Head
def forward_features(self, x):
x = self.patch_embed(x) # 1. Patch embedding
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1) # 2. Prepend class token
x = x + self.pos_embed # 3. Add positional embedding
x = self.pos_drop(x)
x = self.blocks(x) # 4. Transformer Encoder
x = self.norm(x) # 5. LayerNorm
return x[:, 0] # 6. Return class token
def forward(self, x):
x = self.forward_features(x) # Feature extraction
x = self.head(x) # Classification
return xKernkomponenten von ViT:
PatchEmbed (Patches einbetten): Das Bild wird in mehrere kleine Patches aufgeteilt, und jeder Patch wird in einen Vektor (Einbettung) mit fester Dimension umgewandelt. (Abschnitt 10.5.2)cls_token (Klassen-Token): Ein lernfähiger Parameter, der als spezielles Token am Anfang der Sequenz der Patch-Einbettungen hinzugefügt wird. Nach dem Durchgang durch den Transformer-Encoder enthält dieses Klassen-Token Informationen (Features), die das gesamte Bild repräsentieren und für die endgültige Klassifizierung verwendet werden.pos_embed (Positionale Einbettung): Lernfähige Parameter, die die Positionsinformationen jedes Patches (und des Klassen-Tokens) darstellen. Da der Transformer die Reihenfolge der Eingabesequenz nicht selbst erkennen kann, müssen positionale Einbettungen verwendet werden, um diese Informationen explizit bereitzustellen. (Abschnitt 10.5.3)blocks (Transformer-Encoder): Es besteht aus mehreren TransformerEncoderLayer.
TransformerEncoderLayer: Dies ist der Kernblock des ViT und besteht aus Multi-Head Selbst-Aufmerksamkeit (Self-Attention) und einem Feed-Forward Network (FFN).
norm (Layer-Normalisierung) : Layer-Normalisierung wird auf die Ausgabe des Transformer-Encoders angewendet.head (Klassifikationskopf): Dies ist eine vollständig verbundene Schicht, die den Klassen-Token als Eingabe erhält, der durch den Transformer-Encoder verarbeitet wurde, um schließlich die Klasse des Bildes vorherzusagen.forward Methode (allgemeiner Ablauf):
forward_features Methode:
self.patch_embed(x): Die Eingangsbilder werden in eine Sequenz von Patch-Einbettungen umgewandelt.self.cls_token) wird am Anfang der Patch-Einbettungssequenz hinzugefügt.self.pos_embed) wird hinzugefügt.self.blocks) geleitet.self.norm) wird angewendet.x[:, 0]), wird zurückgegeben.self.head(x): Der aus forward_features zurückgegebene Klassen-Token wird durch den Klassifikationskopf geleitet, um das endgültige Vorhersageergebnis (Klassifizierung) zu erhalten.Zusammenfassung:
ViT teilt ein Bild in Patches auf und gibt diese als Eingabe an den Transformer-Encoder. Dabei werden Klassen-Token und positionale Einbettungen verwendet, um sowohl globale Informationen des Bildes als auch die Position der Patches zu berücksichtigen. Schließlich wird das Bild mithilfe des Klassen-Tokens klassifiziert.
Wir betrachten ein einfaches Beispiel, wie ViT auf dem CIFAR-10-Datensatz trainiert werden kann. Der folgende Code verwendet PyTorch, um das ViT-Modell zu trainieren und die Verlustfunktion (loss) und Genauigkeit (accuracy) pro Epoche auszugeben.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.models import vit_b_16 # Using vit_b_16 model as an example
from torch.utils.data import DataLoader
# Hyperparameter setup for a simple training run
num_epochs = 5
batch_size = 32
learning_rate = 1e-4
image_size = 224 # ViT input image size
num_classes = 10 # Number of classes in the CIFAR-10 dataset
# Use GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Data loading and preprocessing (using CIFAR-10 dataset)
transform = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # Normalize with CIFAR-10 statistics
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Create ViT model (not using pretrained weights)
model = vit_b_16(pretrained=False, num_classes=num_classes).to(device)
# Define loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=learning_rate)
# Training loop
for epoch in range(num_epochs):
model.train() # Set the model to training mode
running_loss = 0.0
correct_predictions = 0
total_samples = 0
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# Forward and backward passes
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Calculate statistics
running_loss += loss.item()
_, predicted = torch.max(outputs, 1) # Select the class with the highest probability
total_samples += labels.size(0)
correct_predictions += (predicted == labels).sum().item()
# Print every 100 batches.
# if (i + 1) % 100 == 0:
# print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
# Print epoch statistics
epoch_loss = running_loss / len(train_loader)
epoch_accuracy = correct_predictions / total_samples * 100
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {epoch_loss:.4f}, Accuracy: {epoch_accuracy:.2f}%')
print('Training finished!')100%|██████████| 170M/170M [00:21<00:00, 8.09MB/s]
/home/sean/anaconda3/envs/DL/lib/python3.10/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/sean/anaconda3/envs/DL/lib/python3.10/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=None`.
warnings.warn(msg)Epoch [1/5], Step [100/1563], Loss: 2.1349
Epoch [1/5], Step [200/1563], Loss: 1.8978
Epoch [1/5], Step [300/1563], Loss: 1.9483
Epoch [1/5], Step [400/1563], Loss: 2.0783
Epoch [1/5], Step [500/1563], Loss: 1.7614
Epoch [1/5], Step [600/1563], Loss: 1.8051
Epoch [1/5], Step [700/1563], Loss: 1.7448
Epoch [1/5], Step [800/1563], Loss: 1.8347
Epoch [1/5], Step [900/1563], Loss: 1.8127
Epoch [1/5], Step [1000/1563], Loss: 1.7755
Epoch [1/5], Step [1100/1563], Loss: 1.6506
Epoch [1/5], Step [1200/1563], Loss: 1.7523
Epoch [1/5], Step [1300/1563], Loss: 1.5987
Epoch [1/5], Step [1400/1563], Loss: 1.6078
Epoch [1/5], Step [1500/1563], Loss: 1.7110
Epoch [1/5], Loss: 1.8429, Accuracy: 29.66%
Epoch [2/5], Step [100/1563], Loss: 1.4902
Epoch [2/5], Step [200/1563], Loss: 1.5161
Epoch [2/5], Step [300/1563], Loss: 1.4563
Epoch [2/5], Step [400/1563], Loss: 1.5858
Epoch [2/5], Step [500/1563], Loss: 1.6702
Epoch [2/5], Step [600/1563], Loss: 1.5833
Epoch [2/5], Step [700/1563], Loss: 1.4790
Epoch [2/5], Step [800/1563], Loss: 1.6507
Epoch [2/5], Step [900/1563], Loss: 1.6017
Epoch [2/5], Step [1000/1563], Loss: 1.5102
Epoch [2/5], Step [1100/1563], Loss: 1.2946
Epoch [2/5], Step [1200/1563], Loss: 1.3225
Epoch [2/5], Step [1300/1563], Loss: 1.9922
Epoch [2/5], Step [1400/1563], Loss: 1.3685
Epoch [2/5], Step [1500/1563], Loss: 1.4852
Epoch [2/5], Loss: 1.5410, Accuracy: 42.69%
Epoch [3/5], Step [100/1563], Loss: 1.2692
Epoch [3/5], Step [200/1563], Loss: 1.1648
Epoch [3/5], Step [300/1563], Loss: 1.2412
Epoch [3/5], Step [400/1563], Loss: 1.6217
Epoch [3/5], Step [500/1563], Loss: 1.3776
Epoch [3/5], Step [600/1563], Loss: 1.2591
Epoch [3/5], Step [700/1563], Loss: 1.4333
Epoch [3/5], Step [800/1563], Loss: 1.3301
Epoch [3/5], Step [900/1563], Loss: 1.3536
Epoch [3/5], Step [1000/1563], Loss: 1.4488
Epoch [3/5], Step [1100/1563], Loss: 1.3179
Epoch [3/5], Step [1200/1563], Loss: 1.0684
Epoch [3/5], Step [1300/1563], Loss: 1.6526
Epoch [3/5], Step [1400/1563], Loss: 1.1815
Epoch [3/5], Step [1500/1563], Loss: 1.3683
Epoch [3/5], Loss: 1.3836, Accuracy: 49.23%
Epoch [4/5], Step [100/1563], Loss: 1.2601
Epoch [4/5], Step [200/1563], Loss: 1.3277
Epoch [4/5], Step [300/1563], Loss: 1.1337
Epoch [4/5], Step [400/1563], Loss: 1.2273
Epoch [4/5], Step [500/1563], Loss: 1.7351
Epoch [4/5], Step [600/1563], Loss: 1.3826
Epoch [4/5], Step [700/1563], Loss: 1.2639
Epoch [4/5], Step [800/1563], Loss: 1.5757
Epoch [4/5], Step [900/1563], Loss: 1.0702
Epoch [4/5], Step [1000/1563], Loss: 1.3986
Epoch [4/5], Step [1100/1563], Loss: 1.1105
Epoch [4/5], Step [1200/1563], Loss: 1.2621
Epoch [4/5], Step [1300/1563], Loss: 1.4261
Epoch [4/5], Step [1400/1563], Loss: 1.3028
Epoch [4/5], Step [1500/1563], Loss: 1.9051
Epoch [4/5], Loss: 1.2850, Accuracy: 52.98%
Epoch [5/5], Step [100/1563], Loss: 0.9517
Epoch [5/5], Step [200/1563], Loss: 0.9844
Epoch [5/5], Step [300/1563], Loss: 1.2391
Epoch [5/5], Step [400/1563], Loss: 1.3588
Epoch [5/5], Step [500/1563], Loss: 0.9441
Epoch [5/5], Step [600/1563], Loss: 1.1711
Epoch [5/5], Step [700/1563], Loss: 1.1687
Epoch [5/5], Step [800/1563], Loss: 1.0097
Epoch [5/5], Step [900/1563], Loss: 0.9899
Epoch [5/5], Step [1000/1563], Loss: 1.3289
Epoch [5/5], Step [1100/1563], Loss: 1.5510
Epoch [5/5], Step [1200/1563], Loss: 0.9139
Epoch [5/5], Step [1300/1563], Loss: 0.9221
Epoch [5/5], Step [1400/1563], Loss: 1.3378
Epoch [5/5], Step [1500/1563], Loss: 1.1785
Epoch [5/5], Loss: 1.2116, Accuracy: 55.78%
Training finished!Dieser Code ist ein einfaches Beispiel, um das Funktionsprinzip des ViT-Modells zu veranschaulichen. Das tatsächliche ViT wird erst nach dem Vortrainieren (pre-training) auf großen Datensätzen wie ImageNet für spezifische Aufgaben (z.B. CIFAR-10-Klassifikation) durch Feintuning (fine-tuning) so verwendet, dass es viel bessere Leistungen zeigt. Hier wird einfach nur überprüft, ob ein Training möglich ist.
Bedeutung und Auswirkungen des ViT
Das ViT hat durch seine Überlegenheit in Aufgaben der Bildklassifizierung gegenüber CNNs einen großen Widerhall im Bereich Computer Vision ausgelöst. Insbesondere kam es zu seiner vollen Leistungsfähigkeit, wenn es auf sehr großen Datensätzen wie JFT-300M mit über 300 Millionen Bildern vortrainiert wurde. Dies hat zwei wichtige Schlussfolgerungen nahegelegt:
Skalierbarkeit: Das ViT zeigte eine ausgezeichnete Skalierbarkeit, bei der die Leistung kontinuierlich verbessert wird, wenn die Größe des Datensatzes zunimmt. Dies steht im Gegensatz zu CNN-basierten Modellen, bei denen die Leistungssteigerung bei einer bestimmten Datenmenge stagniert oder sogar abnimmt. Diese Eigenschaft des ViT eröffnet die Möglichkeit, in Zukunft mit noch mehr Daten noch leistungsfähigere Vision-Modelle zu erstellen.
Allgemeingültigkeit von Transformers: Das ViT bewies, dass die Transformer-Architektur, die im Bereich der natürlichen Sprachverarbeitung (NLP) weit verbreitet ist, auch effektiv in der Bildverarbeitung angewendet werden kann. Dies führte zur Entstehung von multimodalen Modellen, die verschiedene Modalitäten (Text, Bilder, Audio usw.) mit einer Architektur verarbeiten können.
Der Erfolg des ViT wurde zu einem wichtigen Grundstein für die Entwicklung multimodaler Modelle wie CLIP (Contrastive Language-Image Pre-training). CLIP kombiniert den Bildencoder von ViT mit einem transformerbasierten Textencoder, um eine vereinte Darstellung von Bildern und Texten in einem Raum zu lernen. Dadurch werden verschiedene Anwendungen ermöglicht, wie die Generierung textbasierter Beschreibungen für Bilder oder das Suchen von Bildern basierend auf textbasierten Beschreibungen.
Ursprünglicher Text:
Übersetzung:
Google Research hat das von ihnen vorgeschlagene und trainierte ViT-22B in der Bildklassifizierung eine bessere Leistung als CNNs gezeigt, was einen großen Widerhall im Bereich des Computer Vision auslöste. ViT-22B bewies, dass die Skalierung der Modell- und Datengröße einer der Kernfaktoren für Leistungsverbesserungen ist. Mit seiner überwältigenden Größe von 22 Milliarden Parametern und einem ultra-großen Datensatz, bestehend aus Milliarden von Bildern, erzielte ViT-22B eine Leistung auf einem bis dahin schwer vorstellbaren Niveau und öffnete neue Horizonte für die visuelle KI.
Entstehungshintergrund: Skalierungsgesetze und der Erfolg großer Sprachmodelle
Das Erscheinen von ViT-22B steht in engem Zusammenhang mit dem erstaunlichen Erfolg riesiger Sprachmodelle (Large Language Model, LLM) im Bereich der natürlichsprachlichen Verarbeitung (NLP). LLMs wie GPT-3 zeigten, dass sie dem Skalierungsgesetz (scaling law) folgen, wonach sich die Leistung stetig verbessert, wenn die Modellgröße (Anzahl der Parameter) und die Datenmenge erhöht werden. Diese Tendenz verbreitete den Glauben, dass “größer besser ist”, was dazu führte, dass类似的尝试也在视觉领域进行。
ViT由于基于Transformer架构,因此很容易应用在LLM中验证的扩展策略。因为ViT具有将图像补丁处理成类似于文本令牌的特性,所以在不大幅改变模型结构的情况下,可以增加参数数量并使用更多数据进行训练。
ViT-22B的结构和特点
ViT-22B基本上遵循了ViT的架构,但在规模上有所不同。
庞大的模型大小: 拥有220亿个参数的ViT-22B与ViT-Base (8600万个), ViT-Large (3.7亿个) 和 ViT-Huge (6.32亿个) 相比,拥有压倒性的规模。这意味着模型能够捕捉到更加复杂和微妙的图像特征,并能内化更多的知识。
超大规模的数据集: ViT-22B使用了由数十亿张图片组成的非公开数据集(如JFT-4B等)进行训练。这些大型数据对于最大化模型的一般化性能(generalization performance)和全面学习各种图像分布至关重要。
改进的性能: ViT-22B在多种视觉基准测试中,包括图像分类、对象检测和图像分割等任务上,取得了比现有任何模型更优异的性能(SOTA, State-of-The-Art),这清楚地表明了模型大小和数据量对性能的积极影响。
ViT-22B训练的挑战与启示
像ViT-22B这样的超大规模模型的训练在普通的研究环境中几乎是不可能的。需要数百乃至数千个昂贵的专用硬件如GPU或TPU,且训练时间可能持续几周到几个月不等。此外,存储和处理大量数据所需的基础设施建设也是一个巨大的挑战。
ViT-22B的出现证明了ViT架构的可扩展性(scalability),但同时也提出了对效率(efficiency)的思考。随着模型规模的增大,虽然性能会提高,但训练及推理(inference)所需计算资源和能源消耗也会呈指数级增长。因此,预计未来的研究将朝着在保持模型性能的同时提高效率的方向发展。
(Note: The section on MAE v3 was not translated as the original content was not provided in the request.)
Correction Note: There was a mix-up at the end of the translation where some sentences were left in Chinese, particularly from “这意味着模型能够捕捉到更加复杂和微妙的图像特征…” onwards. Below is the corrected version for that part:
Bedeutungsvolle Modellgröße: Mit 22 Milliarden Parametern überragt ViT-22B die Größenordnung von ViT-Base (86 Millionen), ViT-Large (370 Millionen) und ViT-Huge (632 Millionen). Dies bedeutet, dass das Modell komplexere und subtilere Bildmerkmale erfassen kann und mehr Wissen internalisieren kann.
Ultragroßer Datensatz: ViT-22B wurde mit einem nicht öffentlichen Datensatz trainiert, der aus Milliarden von Bildern besteht (z.B. JFT-4B). Solche großen Datenmengen sind entscheidend für die Maximierung der Generalisierungsleistung und das umfassende Lernen von verschiedenen Bildverteilungen.
Verbesserte Leistung: ViT-22B zeigte in mehreren visuellen Benchmarks, einschließlich Bildklassifizierung, Objekterkennung und Bildsegmentierung, überlegene Leistungen (SOTA, State-of-The-Art) im Vergleich zu bestehenden Modellen. Dies deutet klar auf den positiven Einfluss von Modellgröße und Datenmenge auf die Leistung hin.
Herausforderungen und Implikationen des Trainings von ViT-22B
Das Training von ultragroßen Modellen wie ViT-22B ist in typischen Forschungsumgebungen fast unmöglich. Es erfordert hunderte bis tausende teurer Spezialhardware wie GPU oder TPU, und die Trainingszeit kann von einigen Wochen bis zu mehreren Monaten reichen. Zudem stellt die Erstellung der Infrastruktur zur Speicherung und Verarbeitung riesiger Datenmengen eine enorme Herausforderung dar.
Die Einführung von ViT-22B hat zwar die Skalierbarkeit der ViT-Architektur bewiesen, wirft jedoch auch Fragen nach Effizienz auf. Mit zunehmender Modellgröße verbessert sich zwar die Leistung, aber die für das Training und die Inferenz erforderlichen Rechenressourcen und Energieverbrauch steigen exponentiell. Daher wird erwartet, dass zukünftige Forschungen darauf abzielen, die Effizienz zu erhöhen, während die Modelleffizienz beibehalten wird. Meta AI (Facebook AI Research, FAIR)-Team hat den MAE (Masked Autoencoder) vorgeschlagen, eine Methode des selbstüberwachten Lernens (self-supervised learning), die starke Bildrepräsentationen aus großen Mengen an unmarkierten Bilddatensätzen lernt. Der MAE basiert auf ViT und maskiert einen beträchtlichen Teil eines Bildes zufällig, um das Modell zu trainieren, die verdeckten Teile zu rekonstruieren. MAE v3 ist die neueste Version von MAE, die durch verschiedene Verbesserungen die Leistung und Effizienz weiter erhöht hat.
Funktionsweise des MAEs
Das Kernprinzip des MAEs besteht darin, das Modell so zu trainieren, dass es, ähnlich wie ein Mensch “Lücken füllt”, ein ganzes Bild versteht und rekonstruiert, indem es nur einen Teil der Informationen des Bildes sieht.
Zufälliges Maskieren des Eingangsbildes: Ein beträchtlicher Teil (z. B. 75%) des Eingangsbildes wird zufällig maskiert. Dies geschieht in Patch-Einheiten.
Codierung (Encoding): Nur die nicht maskierten, also sichtbaren Patches werden dem ViT-Encoder eingegeben, um Feature-Vektoren zu extrahieren.
Decodierung (Decoding): Die Ausgabe des Encoders (Feature der sichtbaren Patches) und Informationen über die maskierten Patches werden zusammen verwendet, um das Originalbild wiederherzustellen. Dabei besteht der Decoder aus leichten (lightweight) Transformer-Blöcken, um die Recheneffizienz zu steigern.
Rekonstruktionsverlust (Reconstruction Loss): Der Pixelunterschied zwischen dem rekonstruierten Bild und dem Originalbild (z. B. Mean Squared Error, MSE) wird berechnet, und das Modell (Encoder und Decoder) wird so trainiert, dass dieser Unterschied minimiert wird.
Strukturelle Verbesserungen von MAE v3
MAE v3 hat durch die folgenden Hauptverbesserungen eine bessere Leistung und Effizienz als frühere Versionen erzielt.
Verbesserte Maskierungsstrategie: Im ursprünglichen MAE wurden Patches einfach zufällig maskiert, während MAE v3 raffinierteere Maskierungsstrategien verwendet. Zum Beispiel kann das Maskieren so gestaltet werden, dass bedeutungsvolle Bereiche (wie Objektrandbereiche) besser erhalten bleiben oder Patches von unterschiedlicher Größe maskiert werden.
Optimierte Encoder-Decoder-Architektur
Erweiterung der Modellgröße: Die Modellgröße wurde erweitert, um größere Mengen an Daten zu verarbeiten.
Vorteile und Bedeutung des MAEs
MAE wird in der Community des selbstüberwachten Lernens aufgrund folgender Vorteile geschätzt:
Lernen ohne Labels: MAE kann vorab trainiert werden, indem es große Mengen an unmarkierten Bilddatensätzen verwendet. Dies spart Kosten und Zeit für die manuelle Markierung von Daten und ermöglicht es, mehr Daten zu nutzen.
Starke Repräsentationslernen: Durch das Training zur Rekonstruktion von Bildern, bei denen ein beträchtlicher Teil maskiert ist, entwickelt MAE Fähigkeiten, die Struktur, Bedeutung und Kontext von Bildern zu verstehen. Diese Fähigkeiten helfen, bessere Leistungen in verschiedenen Downstream-Tasks wie Bildklassifizierung, Objekterkennung und Segmentierung zu erzielen.
Einfache Transfer-Learning: Vorab trainierte MAE-Modelle können für verschiedene Aufgaben feinjustiert (fine-tuned) werden, was auch in Fällen mit fehlenden Labels gute Leistungen ermöglicht.
Fazit MAE hat durch die intuitive Idee des “Lückenfüllens” eine effektive Methode vorgestellt, um starke Bildrepräsentationen ohne Labels zu lernen. MAE v3 baut auf diesen Stärken von MAE auf und erreicht eine noch höhere Leistung und Effizienz, während es die Entwicklung der selbstüberwachten Lernforschung voranbringt.
2021 veröffentlichte OpenAI in der Arbeit “Learning Transferable Visual Models From Natural Language Supervision” das CLIP (Contrastive Language-Image Pre-training) Modell. CLIP hat durch die Lernmethode, Bilder und Text, zwei verschiedene Modalitäten (modality), in einen gemeinsamen Raum (shared space) zu drücken, eine revolutionäre Entwicklung im Bereich des multimodalen Lernens bewirkt.
Der Kern von CLIP ist die Struktur eines doppelten Encoders, bestehend aus einem Bild-Encoder (Image Encoder) und einem Text-Encoder (Text Encoder), zwei unabhängigen Encodern.
Diese beiden Encodern werden durch kontrastives Lernen (contrastive learning) trainiert.
Kern der CLIP-Trainings: Kontrastives Lernen (Contrastive Learning)
Der Kern der CLIP-Trainingssitzung ist das kontrastive Lernen mit Hilfe eines großen Datensatzes von Bild-Text-Paaren.
Code-Beispiel
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class CLIP(nn.Module):
def __init__(self, image_encoder, text_encoder, embed_dim):
super().__init__()
self.image_encoder = image_encoder
self.text_encoder = text_encoder
self.image_projection = nn.Linear(image_encoder.output_dim, embed_dim)
self.text_projection = nn.Linear(text_encoder.output_dim, embed_dim)
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07)) # Learnable scale parameter
def forward(self, images, texts):
# 1. Image encoding
image_features = self.image_encoder(images) # [batch_size, image_encoder.output_dim]
image_embeddings = self.image_projection(image_features) # [batch_size, embed_dim]
image_embeddings = F.normalize(image_embeddings, dim=-1) # L2 normalization
# 2. Text encoding
text_features = self.text_encoder(texts) # [batch_size, text_encoder.output_dim]
text_embeddings = self.text_projection(text_features) # [batch_size, embed_dim]
text_embeddings = F.normalize(text_embeddings, dim=-1) # L2 normalization
# 3. Similarity calculation
logits_per_image = self.logit_scale.exp() * image_embeddings @ text_embeddings.t() # [batch_size, batch_size]
logits_per_text = logits_per_image.t() # [batch_size, batch_size]
return logits_per_image, logits_per_text
def contrastive_loss(logits_per_image, logits_per_text):
"""
Calculates the Contrastive Loss
"""
batch_size = logits_per_image.shape[0]
labels = torch.arange(batch_size).to(logits_per_image.device) # Correct labels (diagonal: same pair)
loss_i = F.cross_entropy(logits_per_image, labels) # Loss based on image
loss_t = F.cross_entropy(logits_per_text, labels) # Loss based on text
return (loss_i + loss_t) / 2 # Average lossDer Bildencoder von CLIP nimmt ein Bild als Eingabe und wandelt es in einen Einbettungsvektor fester Dimension um. Im ursprünglichen CLIP-Papier wurden sowohl ResNet als auch ViT (Vision Transformer) getestet.
Die Experimente ergaben, dass der ViT-basierte Encoder eine bessere Leistung als der ResNet-basierte Encoder zeigte. Insbesondere zeigte sich, dass die Leistungssteigerung von ViT größer wurde, je größer das Modell und die Datenmenge waren.
Der Textencoder von CLIP nimmt eine textuelle Beschreibung als Eingabe und wandelt sie in einen Einbettungsvektor der gleichen Dimension wie der Bildencoder um. Im ursprünglichen CLIP-Papier wurde ein Transformer-basierter Textencoder verwendet.
Eine der wichtigsten Eigenschaften von CLIP ist die Fähigkeit zur Zero-shot Transfer, d.h., es zeigt ausgezeichnete Leistungen bei verschiedenen Bildklassifizierungsaufgaben ohne zusätzliche Feinabstimmung (fine-tuning).
Gründe für den Zero-shot Transfer
CLIP lernt während des Prozesses des kontrastiven Lernens anhand eines großen Datensatzes von Bilder-Text-Paaren, Methoden, um Bilder und Texte im gleichen semantischen Raum darzustellen. D.h., CLIP entwickelt die Fähigkeit, semantische Zusammenhänge zwischen Bildern und Texten zu erfassen.
Prozess des Zero-shot Klassifizierens
Bedeutung des Zero-shot Transfers
Der Zero-shot Transfer bedeutet, dass das Modell in der Lage ist, auf neue Klassen oder Aufgaben angewendet zu werden, die es während des Trainings nicht gesehen hat, ohne zusätzliches Lernen oder Feinabstimmung (fine-tuning). Dies steht im Gegensatz zur traditionellen überwachten Lernmethode, die für bestimmte Aufgaben gekennzeichnete Daten erfordert.
Der Kern des Zero-shot Transfers ist die Flexibilität. Zum Beispiel kann ein Bildklassifizierungsmodell, das nur mit Daten von “Katzen” und “Hunden” trainiert wurde, auch Bilder von Klassen wie “Giraffen” oder “Elefanten”, die nicht in den Trainingsdaten vorhanden waren, korrekt klassifizieren, wenn es entsprechende natürlichsprachliche Beschreibungen wie “Bild einer Giraffe” oder “Bild eines Elefanten” bereitgestellt bekommt. So kann das Modell seine Generalisierungsfähigkeit durch natürlichsprachliche Beschreibungen maximieren, auch wenn für neue Klassen oder Aufgaben keine Daten vorhanden sind. Dies ist die größte Stärke des Zero-shot Transfers. Darüber hinaus bietet Zero-Shot-Transfer Flexibilität. Er kann nicht nur für die Bildklassifizierung, sondern auch für Bildsuche, Bildunterschriftenerstellung, Objekterkennung (Object Detection), visuelle Frage-Antwort-Systeme (Visual Question Answering, VQA) und andere multimoale Aufgaben angewendet werden. Zum Beispiel kann in einem Bildsuchsystem ein Textabfrage wie “roter Sportwagen” eingegeben werden, und das Modell findet die dazugehörigen Bilder von roten Sportwagen in der Datenbank. Dies ist möglich, weil das Modell die semantische Beziehung zwischen Bildern und Text verstehen kann. Auf diese Weise trägt die Verwendung eines einzigen Modells für verschiedene Aufgaben zur Zeit- und Ressourcenschonung bei und erhöht die Effizienz von KI-Systemen.
Der Einfluss von CLIP
CLIP hat durch seine Zero-Shot-Transferfähigkeiten neue Möglichkeiten im Bereich des multimodalen Lernens geöffnet. Seitdem wurden verschiedene nachfolgende Studien auf der Basis der Ideen von CLIP durchgeführt, die zur Entwicklung von Bildgenerierungsmodellen wie DALL-E und Stable Diffusion sowie großmaßstäblichen multimoalen Modellen wie GPT-4V beigetragen haben.
Contrastive Learning ist eine leistungsstarke Methode zum Lernen von Repräsentationen aus unbeschrifteten Daten. Insbesondere zeigt es hervorragende Ergebnisse im multimodalen Lernen, das verschiedene Modalitäten wie Bilder und Texte verbindet. In diesem Deep Dive analysieren wir die grundlegenden Prinzipien des Contrastive Learnings, verschiedene Ansätze und den bahnbrechenden Modell CLIP (Contrastive Language-Image Pre-training), das auf Contrastive Learning basiert und Bilder und Texte verbindet.
Das Kernkonzept von Contrastive Learning ist es, ähnliche Stichprobenpaare (positive Paare) im Embedding-Raum nahe beieinander zu bringen, während unähnliche Stichprobenpaare (negative Paare) weit voneinander entfernt sind.
Contrastive Learning durchläuft in der Regel folgende Schritte:
Es wurden verschiedene Contrastive Loss Funktionen vorgeschlagen, von denen folgende Beispiele hervorstechen:
InfoNCE Loss (Noise Contrastive Estimation): Ähnlich wie Cross-Entropy-Loss maximiert es die Softmax-Wahrscheinlichkeit für positives Paar.
\(L = -\log \frac{\exp(\text{sim}(z_i, z_j) / \tau)}{\sum_{k=1}^{2N} \mathbb{1}_{[k \neq i]} \exp(\text{sim}(z_i, z_k) / \tau)}\)
NT-Xent Loss (Normalized Temperature-scaled Cross Entropy Loss): Eine Variante des InfoNCE-Loss, die in der SimCLR-Paper vorgeschlagen wurde.
Triplet Loss: Es wird gelernt, dass der Abstand zwischen Anchor und Positivem kleiner ist als der Abstand zwischen Anchor und Negativem.
\(L = \max(0, d(a, p) - d(a, n) + m)\)
\(a\): Anchor
\(p\): Positives Beispiel
\(n\): Negatives Beispiel
\(d(\cdot, \cdot)\): Distanzfunktion (z.B., Euklidischer Abstand)
\(m\): Margen (bestimmt, wie weit die Distanz sein sollte)
CLIP ist ein von OpenAI entwickeltes Modell, das Contrastive Learning verwendet, um eine starke multimodale Repräsentation zu lernen, die Bilder und Texte verbindet.
Contrastive Learning ist eine effektive Methodologie, um starke Darstellungen aus unlabeled Daten zu lernen. Insbesondere hat CLIP Contrastive Learning erfolgreich auf multimodales Lernen angewendet und neue Horizonte im Verbinden von Bildern und Text eröffnet. Contrastive Learning und CLIP werden in Zukunft wahrscheinlich in verschiedenen Bereichen eingesetzt.
Literaturhinweise: * Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. (2020). Ein einfaches Framework für kontrastives Lernen visueller Darstellungen. International conference on machine learning. PMLR. * Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021). Lernen übertragbarer visueller Modelle durch Überwachung mit natürlicher Sprache. International Conference on Machine Learning. PMLR. * He, K., Fan, H., Wu, Y., Xie, S. & Girshick, R. (2020). Momentum Contrast für unüberwachtes Lernen visueller Darstellungen. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (S. 9729-9738). * Grill, J. B., Strub, F., Altché, F., Tallec, C., Richemond, P., Buchatskaya, E., … & Valko, M. (2020). Bootstrap your own latent - ein neuer Ansatz für selbstüberwachtes Lernen. Advances in neural information processing systems, 33, 21271-21284.
Grundfragen
Anwendungsfragen
blip-image-captioning-base nutzen).Tiefgangfragen
VQA Modellstruktur:
graph LR
subgraph VQA Modell
A[Bild] --> B(Bildencoder - CNN)
C[Fragetext] --> D(Textencoder - RNN/Transformer)
B --> E(Fusionierungsmodul)
D --> E
E --> F(Decoder - RNN/Transformer)
F --> G(Antwort)
endCLIP Lernmethode und Vorteile:
Hugging Face Transformers Bildunterschrift-Code:
from transformers import pipeline
captioner = pipeline("image-to-text", model="nlpconnect/vit-gpt2-image-captioning") # oder "blip-image-captioning-base"
image_path = "path/to/your/image.jpg" # Pfad zur Bilddatei
caption = captioner(image_path)[0]['generated_text']
print(caption)Multimodale Fusionstechniken:
Cross-Modal Attention:
Textbasierte Bildgenerierungsmodelle (DALL-E, Stable Diffusion usw.):
CLIP (Learning Transferable Visual Models From Natural Language Supervision): Das Originalpapier zu CLIP, einer Methode zum Lernen multimodaler Darstellungen, die Bilder und Texte verbindet. https://arxiv.org/abs/2103.00020
ViT (An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale): Das Originalpapier zu ViT, das zeigt, wie man mit der Transformer-Architektur ohne CNNs hervorragende Leistungen in der Bildklassifizierung erzielen kann. https://arxiv.org/abs/2010.11929
DALL-E (Zero-Shot Text-to-Image Generation): Das Papier zum DALL-E-Modell, das Bilder auf Basis von Textbeschreibungen generiert. https://arxiv.org/abs/2102.12092
MAE (Masked Autoencoders Are Scalable Vision Learners): Das Papier zu MAE, das die Lernung visueller Darstellungen durch Maskierung und Rekonstruktion von Bildteilen beschreibt. https://arxiv.org/abs/2111.06377
Visual Question Answering (VQA): Eine der frühen VQA-Studien, die den VQA-Datensatz und Baseline-Modelle präsentiert. https://arxiv.org/abs/1505.00468
Show, Attend and Tell (Neural Image Caption Generation with Visual Attention): Das Papier, das erstmals die Aufmerksamkeitsmechanismen in der Bildbeschreibung einführte. https://arxiv.org/abs/1502.03044
Multimodal Machine Learning: A Survey and Taxonomy: Ein umfassendes Überblickspapier zum multimodalen Maschinelles Lernen. https://arxiv.org/abs/1705.09406
A Tutorial on Multimodal Deep Learning, Jiquan Ngiam: Ein Tutorium zum multimodalen Tiefenlernen von NeurIPS 2011 (Video). https://www.youtube.com/watch?v=cR_ACqfF-bY&list=PL_45CaSOtPzL-HWxMcnr02KvmP9Gq-xdb
CMU Multimodal Machine Learning Course (11-777, Spring 2023), Louis-Philippe Morency: Kursmaterialien zur mehrmodalen Maschinelles Lernen an der Carnegie Mellon University. https://cmu-multicomp-lab.github.io/mmml-course/spring2023/
A Comprehensive Survey on Deep Multimodal Learning: Überblicksartikel über tiefe mehrmodale Lernverfahren aus dem Jahr 2022. https://arxiv.org/abs/2204.11984
arXiv: Suche nach aktuellen Forschungspapieren zur mehrmodalen Lernverfahren. Verwenden Sie Schlagwörter wie “multimodal learning”, “vision-language” usw. https://arxiv.org/
Hugging Face Transformers Multimodal Documentation: Dokumentation zu den mehrmodalen Modellen in der Hugging Face Transformers-Bibliothek. https://huggingface.co/docs/transformers/main/en/model_doc/auto#multimodal-models
Original text: 네, 이해했습니다. 다음과 같이 번역하겠습니다.
| 한국어 | 독일어 |
|---|---|
| 안녕하세요! | Hallo! |
| 어떻게 도와드릴까요? | Wie kann ich Ihnen helfen? |
| 감사합니다. | Vielen Dank. |
\(E = mc^2\)
\[\int_0^\infty f(x) dx\]
Translation:
| Koreanisch | Deutsch |
|---|---|
| Hallo! | Hallo! |
| Wie kann ich Ihnen helfen? | Wie kann ich Ihnen helfen? |
| Vielen Dank. | Vielen Dank. |
\(E = mc^2\)
\[\int_0^\infty f(x) dx\]